Ведение логов встречается повсеместно, от небольших стартапов, состоящих из одного человека, до крупных компаний. Даже простой вопрос алгоритмического программирования подразумевает ведение журнала.
Мы сильно зависим от логов для разработки, поддержки и обеспечения работы наших программ. Однако мало кто уделяет внимание их правильному проектированию. Часто логирование рассматривается второстепенно — его добавляют в код словно магический порошок, чтобы облегчить повседневную эксплуатацию системы.
Любой код со временем превращается в технический недочет, и логирование — не исключение. Логи быстро устаревают, и в итоге мы чаще исправляем ошибки, вызванные логами, чем получаем полезную информацию от них.
Как же навести порядок в логировании и превратить его в союзника, а не в проблему из прошлого?
Что такое логирование?
Вот интересное определение из статьи Колина Эберхардта:
Логирование — это процесс записи действий и состояния приложения во вспомогательный интерфейс.
Логирование вплетается в систему именно так. Мы, похоже, соглашаемся, что логи не относятся к конкретному слою системы, а являются общей функциональностью, разделяемой между различными компонентами приложения.
Простая схема, на которой протоколирование вписано в систему с чистой архитектурой, будет выглядеть примерно так:
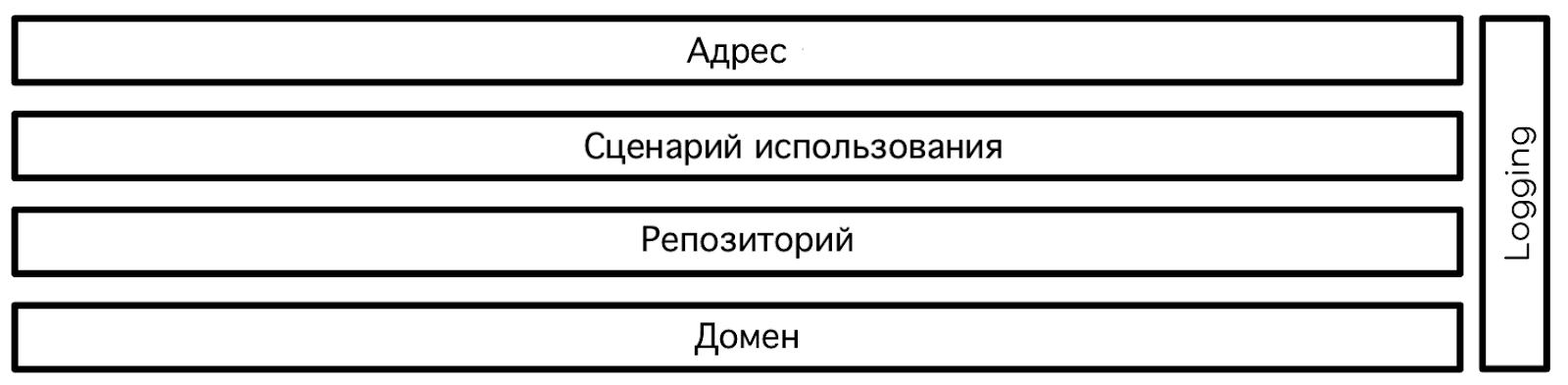
Можно с уверенностью сказать, что ведение журнала само по себе является подсистемой в нашем приложении. И мы можем с уверенностью сказать, что без тщательного рассмотрения она часто выходит из-под контроля быстрее, чем мы думаем.
Хотя в том, что логирование является подсистемой приложения, нет ничего плохого, традиционное восприятие логирования (с 4-6 уровнями info, warn, error, debug и так далее) часто заставляет разработчиков сосредоточиться не на том, на чем нужно. Оно заставляет нас сосредоточиться на формате, а не на фактической цели, для которой мы пишем журналы.
Это одна из причин, почему мы выводим ошибки, не задумываясь о том, как их обрабатывать. Это также причина, по которой мы ведем журнал на каждом шаге нашего кода и, по иронии судьбы, не можем эффективно отлаживать его в случае возникновения проблем на производстве.
Именно поэтому предлагаем альтернативный фреймворк для протоколирования и, в свою очередь, то, как мы можем надежно спроектировать протоколирование в наших системах.
Хорошее, плохое и ужасное
Это схема того, как, по моему мнению, мы должны выстраивать стратегию ведения журнала. В ней есть три - и только три - категории или проблемы для наших журналов.
Первое правило ведения журнала: не вести журнал
Чрезмерное ведение логов вредит продуктивности наших команд и их способности справляться с обычными операциями.
Есть масса причин, по которым мы не должны «логировать при любой возможности», как советуют некоторые фанаты наблюдаемости. Ведение логов означает большее количество кода, который нужно поддерживать, оно влечет за собой расходы на производительность системы, а ведение логов подвергает нас большему количеству проверок на предмет конфиденциальности данных.
Тем не менее, не советуем полностью отказаться от ведения журналов. Ведение журналов при правильном использовании может существенно помочь нам обеспечить надежную работу наших систем.
Предлагаем начать без протоколирования и работать по нарастающей, чтобы определить места, где нам нужно протоколировать, а не «протоколировать везде, так как нам может понадобиться посмотреть на них».
Мое эмпирическое правило при добавлении строки журнала: «Если мы не можем определить точную причину или сценарий, когда мы будем смотреть на журнал, не записывайте».
С учетом сказанного, как мы можем безопасно внедрить ведение журнала, когда это абсолютно необходимо? Как мы должны структурировать наши журналы и оформлять их содержимое? Какую информацию необходимо включать в журналы?
Ужасный журнал
Это первый тип журналов, который можно встретить реже всего. (Если мы находим их слишком часто, то, возможно, в наших системах есть более серьезные проблемы!)
«Ужасные» журналы — это журналы катастрофических или неожиданных сценариев, которые требуют немедленных действий (например, катастрофические ошибки, требующие перезапуска приложения). Можно утверждать, что при таких обстоятельствах имеет смысл использовать инструменты оповещения, такие как Sentry.
Тем не менее, журнал ошибок все еще может быть полезен, чтобы предоставить нам больше контекста вокруг этих ошибок, который недоступен в их стековой трассировке. Но они могут помочь в воспроизведении этих ошибок, например, пользовательского ввода.
Как и ошибки, которые они сопровождают, эти журналы должны быть сведены к минимуму в нашем коде и размещены в одном месте. Они также должны быть разработаны/документированы в спецификации как обязательное поведение системы для обработки ошибок. Кроме того, они должны быть вплетены в исходный код, где происходит обработка ошибок.
Хотя формат и уровень «уродливых» журналов полностью зависит от конкретной команды, я бы рекомендовал использовать log.error или log.fatal до изящного выключения и перезапуска приложения. Также следует приложить полную трассировку стека ошибки и входные данные функции или запросов для воспроизведения в случае необходимости.
Плохой журнал
«Плохие» журналы -—это журналы, в которых рассматриваются ожидаемые ошибки, такие как проблемы с сетью и валидация пользовательского ввода. Этот тип журналов требует внимания разработчиков только в случае возникновения аномалии.
Вместе с монитором, настроенным на оповещение разработчиков об ошибке, эти журналы удобны для смягчения потенциальных серьезных проблем с инфраструктурой или безопасностью.
Этот тип журнала также должен быть указан в технических требованиях к обработке ошибок, и его можно объединить, если мы обрабатываем ожидаемые и неожиданные ошибки в одном и том же месте кода.
В зависимости от характера того, что они делают «видимым» для разработчиков, log.warn или log.error могут быть использованы для «плохих» журналов, если команда придерживается определенной конвенции.
Хороший журнал
Последний, но, безусловно, не менее важный, «Хороший» тип журнала, который должен чаще всего появляться в нашем исходном коде - но его зачастую сложнее всего сделать правильно. «Хорошие» журналы - это журналы, связанные со „счастливыми“ этапами работы наших приложений, свидетельствующие об успешном выполнении операций.
В силу самой своей природы, указывающей на начало/успешное выполнение операций в нашей системе, «Хорошие» часто злоупотребляются разработчиками, которые соблазняются мантрой: «Еще один бит данных в журнале, он может нам пригодиться».
И снова я возвращаюсь к нашему самому первому правилу ведения журнала: «Не ведите журнал, если вам это не нужно». Чтобы не допустить такого рода избыточного протоколирования, мы должны документировать «Добро» как часть наших технических требований, дополняющих основную бизнес-логику.
Кроме того, каждый из «хороших» журналов, которые находятся в нашем техническом задании, должен пройти лакмусовую бумажку: есть ли обстоятельства, при которых мы будем смотреть на этот журнал (будь то запрос в службу поддержки, запрос внешнего аудитора)? Только в этом случае log.info не станет страшным наследием, заслоняющим разработчикам видение наших приложений.
Остальное, что вам нужно знать
Полагаю, вы уже заметили, что общая тема предложенной мною стратегии ведения журналов сводится к четкому и конкретному документированию цели ведения журнала. Важно, чтобы мы рассматривали ведение журнала как часть наших требований, и чтобы мы точно определили, какие ключевые слова и сообщения мы хотим помечать в контексте каждого журнала, чтобы они эффективно индексировались.
Только так мы сможем быть в курсе каждого журнала, который мы создаем, и, в свою очередь, иметь четкое представление о наших системах.
Поскольку журналы становятся первоклассными инструкциями с конкретными техническими требованиями в наших спецификациях, это приведет к тому, что их нужно будет
- поддерживать и обновлять по мере развития бизнеса и технических требований
- проводить модульные и интеграционные тесты.
Это может показаться большим объемом дополнительной работы, чтобы сделать наши журналы правильными. Однако я утверждаю, что именно такого внимания и усилий заслуживает ведение журналов, чтобы они могли быть полезными.
Практическое руководство по миграции
Нет смысла в новой стратегии ведения логов (или в любых других новых стратегиях/фреймворках) для старых проектов, если нет возможности перевести их из беспорядочного состояния в идеальное.
Поэтому у нас есть общий план из трех шагов для тех, кто разочарован логами своей системы и готов потратить время на более эффективное ведение логов.
Определите обычных подозреваемых
Поскольку идея состоит в том, чтобы уменьшить количество мусорных логов, первым шагом будет определение того, где прячутся преступники. С помощью мощных текстовых редакторов и IDE, которыми мы сегодня располагаем (или grep, если вы читаете это в прошлом через окно в будущее), можно легко определить все случаи ведения логов.
Документ (или электронная таблица, если вы хотите быть организованным), документирующий все эти случаи регистрации, может понадобиться, если их слишком много.
Исключите все плохие логи
После выявления всех подозреваемых пришло время отсеять плохие яблоки. Дублирующиеся или недоступные журналы - это низко висящие плоды, которые мы можем немедленно исключить из нашего исходного кода.
Что касается остальных случаев ведения логов, то пора привлечь других заинтересованных лиц. Например, инженера, который начал проект (если это возможно), менеджеров по продукту, службу поддержки клиентов или специалистов по соблюдению нормативных требований, чтобы ответить на вопрос: Нужен ли нам каждый из этих журналов, и если да, то для чего они используются?
Подведем итог
Теперь, когда у нас есть суженный список абсолютно необходимых журналов, превращение их в технические требования с документированным назначением каждого из них необходимо для заключения контракта (или мы можем назвать его спецификацией) для нашей подсистемы протоколирования. Спросите себя, что делать, когда происходит log.error, и для кого мы ведем log.info?
