Денормализация базы данных — это метод, используемый для улучшения производительности доступа к данным. Когда база данных нормализована, и такие методы, как индексация, недостаточны, денормализация является одним из последних вариантов для ускорения извлечения данных.
узнай больше на курсе
Python программист с нуля
Стань разработчиком на одном из самых популярных языков программирования - Python
В этой статье мы подробнее рассмотрим, что такое денормализация базы данных и какие различные техники используются для ускорения работы базы данных.
Что такое денормализация базы данных?
Денормализация базы данных — это процесс систематического объединения данных для быстрого получения информации. Этот процесс снижает уровень нормальных форм, что приводит к уменьшению целостности данных.
С другой стороны, производительность извлечения данных увеличивается. Вместо выполнения множества дорогостоящих операций JOIN на многочисленных таблицах, денормализация помогает объединить данные, которые часто или логически взаимосвязаны.
Аномалии базы данных появляются из-за более низких нормальных форм. Проблему избыточности решают путем добавления ограничений на уровне программного обеспечения при вводе данных в базу.
Нормализация vs. Денормализация
Нормализация и денормализация — это два разных подхода к изменению структуры базы данных. В таблице приведены основные различия между этими методами:
Нормализация
Денормализация
Функциональность
Удаляет избыточную информацию и ускоряет изменения данных.
Объединяет несколько данных в один блок и ускоряет извлечение данных.
Фокус
Очищает базы данных от избыточных данных.
Избыточные данные добавляются для ускорения выполнения запросов.
Память
Общая производительность оптимизирована и улучшена.
Из-за избыточности память используется неэффективно.
Целостность
Удаление аномалий улучшает целостность БД.
Целостность данных не поддерживается. Присутствуют аномалии базы данных.
Сценарий использования
Используется в базах данных, где часто происходят операции вставки, обновления и удаления, а соединения не слишком затратны.
Нужна для базы данных, которые часто запрашиваются. Например, хранилища данных.
Тип обработки
Онлайн-обработка транзакций (OLTP).
Аналитическая онлайн-обработка (OLAP)
Нормализация базы данных преобразует ненормализованную базу данных через нормальные формы для улучшения структуры данных. В то время как денормализация начинается с нормализованной базы данных и объединяет данные для более быстрого выполнения часто используемых запросов.
Почему и когда следует денормализовать базу данных?
Денормализация базы данных является жизнеспособным методом, когда скорость извлечения данных является важным фактором. Однако этот метод изменяет общую структуру базы данных. Денормализация полезна в следующих сценариях:
Улучшение производительности запросов. Объединение информации добавляет избыточности. Однако количество операций JOIN уменьшается, что повышает производительность запросов.
Удобство управления. Нормализованную базу данных сложно управлять из-за высокой гранулярности. Вместо вычисления значений или соединения их по мере необходимости, денормализация помогает предоставить данные, которые уже доступны.
Ускорение отчетности. Аналитическим данным требуется много вычислений в короткие сроки. Денормализованная база данных для генерации отчетов является отличным решением для быстрого предоставления аналитической информации.
Если база данных имеет низкую производительность, денормализация не всегда является правильным решением. Поскольку процесс изменяет структуру базы данных, существующие функции могут нарушиться.
Примечание: Проблемы базы данных часто возникают из-за плохо спроектированной структуры. Рассмотрите возможность изучения различных типов баз данных и выбора подходящего варианта для вашего случая использования.
Наличие точки отсчета является важным аспектом при изменении структуры базы данных. В конечном итоге, нормализация базы данных служит в качестве последнего средства, а не быстрого решения.
Техники денормализации
Существует несколько техник денормализации базы данных, в зависимости от конкретного случая использования. Каждая методика имеет свое место применения, преимущества и недостатки.
Предварительное объединение таблиц
Предварительно объединенные таблицы хранят часто используемую информацию в одной таблице. Этот метод полезен, когда:
Запросы часто выполняются на этих таблицах вместе.
Операция соединения затратна.
Метод создает большие избыточности, поэтому важно использовать минимальное количество столбцов и периодически обновлять информацию.
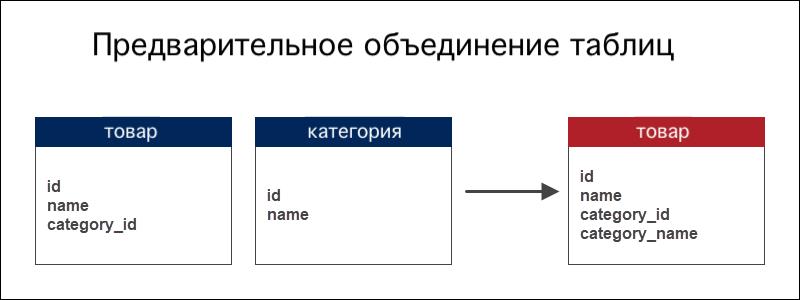
Пример предварительного объединения таблиц:
Магазин хранит информацию о товарах и категориях, к которым эти товары принадлежат. Внешний ключ служит ссылкой на тип товара. Предварительное объединение таблиц добавляет название категории в таблицу товаров.
Зеркальные таблицы
Зеркальная таблица является копией существующей таблицы. Она может быть:
Частичной копией.
Полной копией.
Цель — воспроизвести данные из оригинала в новую таблицу. Создание дубликатов является хорошей техникой для создания резервной копии для сохранения исходного состояния базы данных.
Пример зеркальных таблиц:
Зеркальное копирование таблиц часто используется для подготовки данных в системах поддержки принятия решений. Поскольку запросы обычно агрегируют данные по многим точкам, это может значительно снизить производительность системы.
Разделение таблиц
Разделение таблиц подразумевает деление нормализованных таблиц на два или более отношения. Деление таблиц происходит по двум направлениям:
Горизонтально: таблицы разделяются на подмножества строк с использованием оператора UNION.
Вертикально: таблицы разделяются на подмножества столбцов с использованием оператора INNER JOIN.
Цель метода — разделить таблицы на более мелкие единицы для более быстрого и удобного управления данными. Если в базе данных также содержится оригинальная таблица, этот метод считается особым случаем зеркальных таблиц.
Примеры разделения таблиц:
Наиболее распространенные причины разделения таблиц:
Административные: одна таблица для каждого сектора вместо одной таблицы для всей компании.
Пространственные: одна таблица для каждого региона вместо одной таблицы для всей страны.
Временные: одна таблица для каждого месяца вместо одной таблицы для целого года.
Физические: одна таблица для каждого местоположения вместо одной таблицы для всех мест.
Процедурные: одна таблица для каждого шага в задаче вместо одной таблицы для всей работы.
Хранение вычисляемых значений
Хранение часто выполняемых расчетов оправдано в ситуациях, когда:
Использование вычисляемого значения частое.
Исходные значения не меняются.
Прямое хранение вычисляемых данных обеспечивает уже выполненные вычисления при создании отчета и исключает необходимость поиска исходных значений для каждого запроса.
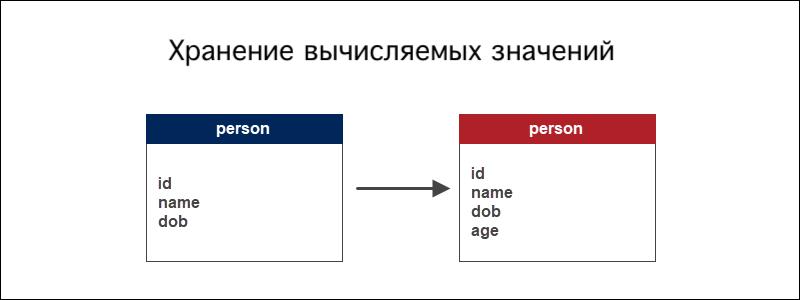
Пример хранения вычисляемых значений:
Если в базе данных есть таблица, отслеживающая информацию о людях, возраст человека является вычисляемым значением на основе даты рождения. Вычислите возраст, найдя разницу между текущей датой с помощью функции CURDATE() и датой рождения.
Иерархические таблицы
Иерархическая таблица представляет собой древовидную структуру с отношением "один ко многим". Одна родительская таблица имеет много дочерних таблиц, но дочерние таблицы имеют только одну родительскую таблицу. Иерархические таблицы используются в случаях, когда:
Структура данных иерархическая.
Родительские таблицы статичны и не изменяются.
Жестко закодированные значения
Жестко закодированные значения удаляют ссылку на часто используемый объект. Используйте этот метод в ситуациях, когда:
Значения считаются статичными.
Количество значений невелико.
Вместо использования небольшой таблицы поиска, значения жестко кодируются прямо в приложение. Этот процесс также избегает необходимости выполнения соединений с таблицей поиска.
Пример жестко закодированных значений:
Таблица с информацией о людях может использовать небольшую таблицу поиска для хранения информации о поле. Поскольку информация в таблице поиска имеет ограниченное количество значений, рассмотрите возможность жесткого кодирования данных непосредственно в таблицу людей.
Хранение деталей с основной таблицей
Основная таблица содержит основную информацию, тогда как другие таблицы содержат конкретные детали. Храните детали с основной таблицей, когда:
Важен детализированный обзор основной таблицы.
Аналитические отчеты по основной таблице частые.
Держать все детали с основной таблицей удобно при выборе данных. Метод лучше всего работает, когда деталей немного. В противном случае процесс извлечения данных значительно замедляется.
Пример хранения деталей с основной таблицей:
Основная таблица с информацией о клиентах обычно хранит конкретные детали о человеке в отдельной таблице. Информация о конкретном местоположении обычно находится в серии меньших таблиц.
Повторяющаяся деталь с основной таблицей
Запросам часто нужна только одна деталь, добавленная к основной таблице, вместо предварительного объединения нескольких значений. Используйте этот метод, когда:
JOIN'ы затратны для одной детали.
Основная таблица требует информации часто.
Добавление одной детали в основную таблицу наиболее распространено, когда база данных содержит исторические данные. Повторяющаяся сущность обычно является самой новой информацией.
Пример единичной детали с основной таблицей:
База данных магазина обычно имеет основную таблицу с информацией о товарах, а другая таблица содержит детали об исторических изменениях цен, включая текущую цену.
Ключи короткого замыкания
В базе данных с тремя или более таблицами связанных данных метод ключей короткого замыкания пропускает промежуточные таблицы и соединяет таблицы предка и потомка напрямую.
Используйте технику короткого замыкания в ситуациях, когда:
База данных имеет более трех уровней мастер-деталь.
Значения из предка и потомка часто нужны, а информация о родителе менее ценна.
Если два отношения связаны через промежуточную таблицу, пропустите JOIN на промежуточное отношение и соедините первую и последнюю таблицы напрямую.
Пример ключей короткого замыкания:
Информационная система может хранить информацию о людях в одной таблице, их адрес в другой, а географическую область этого адреса в третьей таблице. Для любого демографического отчета точный адрес не является критической информацией.
Однако местоположение человека важно для анализа. Короткое замыкание таблицы людей с областью исключает JOIN на промежуточной таблице.
Преимущества денормализации
Скорость. Поскольку запросы JOIN затратны в нормализованной базе данных, извлечение данных происходит быстрее.
Простота. Получение данных становится проще из-за меньшего количества таблиц.
Меньше ошибок. Работа с меньшим количеством таблиц означает меньше ошибок при извлечении информации из базы данных.
Недостатки денормализации
Сложность. Обновление и вставка данных в базу данных становятся более сложными и затратными.
Непоследовательность. Найти правильное значение для информации становится сложнее, так как данные трудно обновлять.
Хранение. Требуется больше места для хранения из-за введенной избыточности.
Итоги
В этой статье мы рассмотрели, что такое нормализация базы данных и как применять ее в различных ситуациях. Тщательно обдумайте причины и методы денормализации. Изменения в базе данных могут быть постоянными и необратимыми.