Что позволяет называть один API как REST API, а другой нет? Сейчас попробуем разложить все по полочкам, чтобы ты на собесе жидко не споткнулся о такую, казалось бы, простую тему.
узнай больше на курсе
Онлайн-курс по Linux
Курс по Linux от Мерион Нетворкс - стань Linux администратором, прокачай свой скиллсет умением работать с операционными системами линукс и сделай большой шаг к DevOps
И так, REST, который расшифровывается как REpresentational State Transfer, а переводится как… - передача репрезентативного состояния. Это архитектурный стиль, который описывает взаимодействие разных частей приложения в сети.
Всю эту балалайку описал один умный мужик по имени Рой Филдинг, он еще был одним из авторов протокола HTTP. Если говорить кратко, то REST, по сути, это набор правил для создания апишек (API).
Кстати, если ты подзабыл что такое API, то глянь наш видос про него. А мы конечно напомним, что API это некое описание того, как программы общаются друг между другом, что можно спросить, что получить в ответ, что и куда для этого присылать.
Так вот, сложив стиль REST и API мы получаем REST API - то есть взаимодействие программ по определенным красивым, как твоя новая стрижка, правилам. Зачем это нужно? А чтобы было удобно и единообразно - когда ты видишь что апи работает по ресту, ты сразу можешь понять как с ним работать и можешь быть уверен, что тебя не будут ждать неприятные сюрпризы.
Погнали разберемся с основными принципами реста.
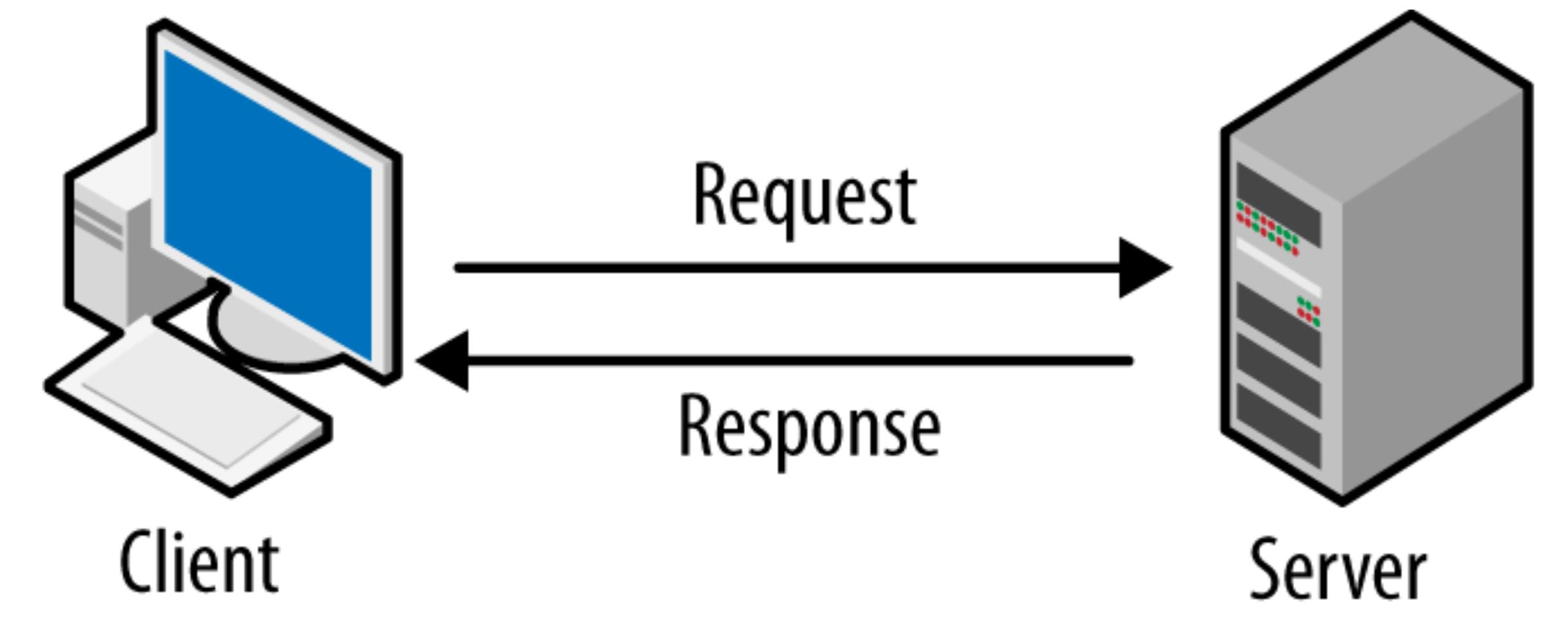
И так, первый - это Клиент-серверная модель (Client-Server). Здесь определяются участники всего этого движа. С одной стороны у нас клиент, который, возможно, всегда прав, но он точно всегда тот, кто запрашивает данные. Это компьютер, сервак, программа, браузер, миска с пловом, да кто угодно - важно толь, что он инициирует запрос.
А с другой стороны сервер - это тот кто принимает запрос от клиента, обрабатывает его, и отправляет ответ с какими-то данными.
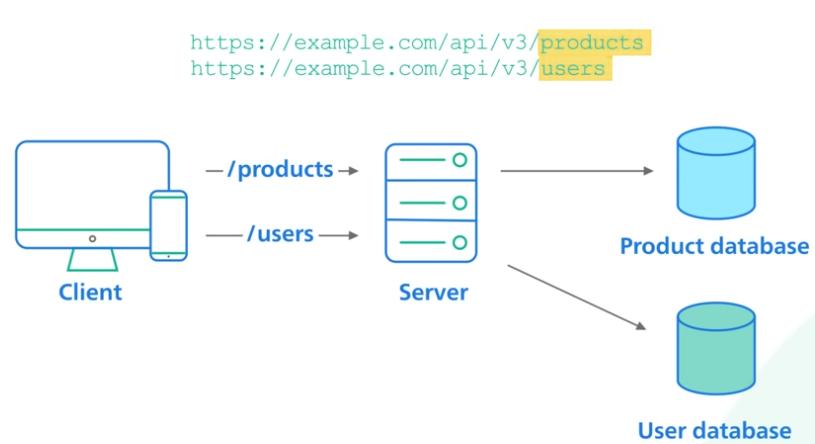
Эти данные в ресте называются ресурсами - это может быть текст, картинка, аудио или видео. Как пример это HTML документ с разметкой страницы или JSON с данными, которые нужно на этой странице отобразить. Эти ресурсы имеют уникальный идентификатор, который обычно представлен в виде URL (Uniform Resource Locator), то есть адреса, и мы можем производить с ними различные действия - получать, обновлять, создавать, удалять, суп наливать, руку чесать.. тьфу, сорри.
В айти тусовке такие действия называют аббревиатурой CRUD - то есть create, read, update, delete. И когда мы говорим про них, мы подразумеваем какую-то сущность - товар, юзер, ну и так далее.
Еще важно, что клиент и сервер независимы друг от друга, каждый делает свое дело и создается отдельно. Это, например, позволяет переписать полностью сервер, и это никак не отразится на клиенте, до тех пор пока формат запросов и ответов остается таким же.
Следующий принцип реста - отсутствие состояния (Stateless). Это про то, что сервер вообще не в курсе о предыдущих запросов от клиента. Поэтому каждый запрос должен содержать всю информацию о том, что нужно клиенту.
Лови пример: зашел ты на сайт магазина выбрать новый телефон
Искал-искал, и оказался на десятой странице каталога. Ты на нее попал, потому что клиент, а именно твой браузер, отправил запрос на сервер по адресу, который выглядел примерно так catalog/phones?page=10
И если ты захочешь вернуться на предыдущую страницу, то ты не можешь сказать серверу “бро, давай назад на одну”, потому что сервер напросто не знает, где ты сейчас и где ты был. Поэтому, тебе нужно снова отправить данные полностью - то есть в нашем случае сделать запрос на catalog/phones?page=9 . Кстати, браузеры помнят, что ты делал, и кнопка назад просто выполняет последний запрос еще раз, поэтому создается ощущение, что мы просто говорим “назад”.
В общем и целом все это нужно для того, чтобы сервер не опупел хранить всю инфу о предыдущих запросах.
Но тут оговоримся: некоторые данные все таки можно хранить, вот только не на сервере, а на клиенте, или на каких-нибудь промежуточных серверах. И это следующий принцип, который называется кешированием (Caching) - он нужен, чтобы разгрузить сервер.
Например, когда он отдаст в ответе картинку, то может сказать, чтобы твой браузер сохранил ее у себя скажем на несколько минут, чтобы каждый раз не запрашивать её - она скорее всего не поменяется, а если и поменяется, то не страшно, когда кэш истечет, то клиент запросит ее снова.
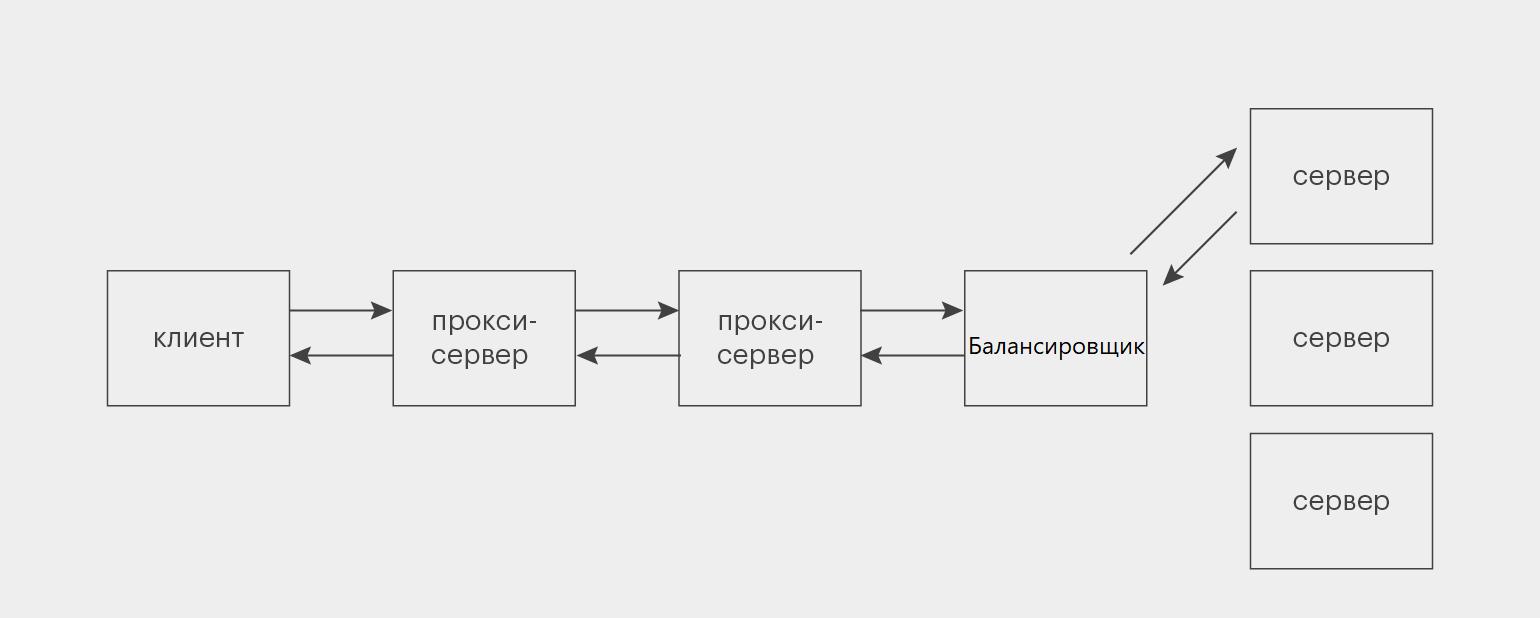
Так, следующий принцип это многоуровневость системы (Layered System). Это значит, что хоть мы и рассматриваем сервер как единую сущность, то на самом деле, там обычно очень много разных серваков - и всякие прокси, и балансировщики нагрузки, но при этом каждый сервер взаимодействует только с ближайшими соседями и не в курсе всего пути запроса и куда отправляет ответ, прям самому клиенту или серверу, который стоит рядышком. Так и клиент не в курсе, запрос который он отправил пришел основному серверу, или это был какой-то промежуточный. То есть вот клиент, вот ближайший сервер - все. Остальное в тумане, и не должно ни на что влиять.
Еще один принцип - единство интерфейса (Uniform Interface). Это про то что клиент и сервер имеют общий и понятный язык для общения между собой. Эм, но как это достигается?
Во-первых, помнишь мы сказали про ресурсы и что у них есть уникальный идентификатор URL? Вот это и оно. Все к чему мы хотим обращаться на сервере должно иметь свой собственный уникальный адрес.
Во-вторых когда клиент отправляет запрос, он должен содержать информацию о том, что нужно сделать, или какие конкретно данные нас интересуют. То есть когда мы отправляем запрос на создание чего-то, например поста в блоге, то наш клиент отправляет все данные о том, каким хочет видеть результат. Если редактируем, то снова отправляем все данные о том, каким хотим видеть результат, даже если часть из них не менялась. Мы как бы работаем тут с единой сущностью поста, и меняем все целиком. То есть запросы типа “Мне только поменять заголовок” тут не приветствуются.
В-третьих, это самодостаточные сообщения. Это значит что в ответе есть все, чтобы клиент понял как его обрабатывать. То есть сервер на запрос фотки группы токио хотел в ответе скажет, что это изображение, и клиент сможет понять, что с ним делать.
Ну и в четвертых, клиенты могут получать информацию о других связанных ресурсах, при помощи гиперссылок в ответе от сервера.
Уууух! И вот если апишка соответствует всем этим принципам, то она гордо называется RESTful API. Звучит это все ну ооочень размыто, но не боись, на примере станет понятнее.
Конечно же все эти принципы можно реализовать при помощи протокола HTTP, и почти всегда если говорят о REST, то подразумевают HTTP.
Теперь давай глядеть как это работает. Вот у нас есть, клиент - это твой браузер, и сервер интернет магазина, где ты собрался покупать новую мобилу.
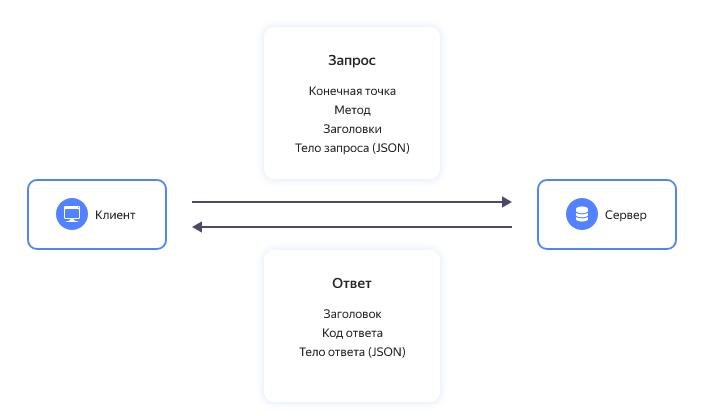
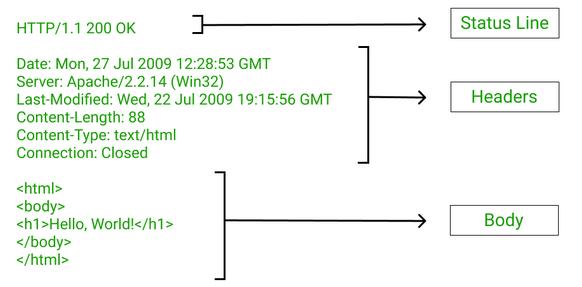
Вот ты уже выбрал какую именно хочешь и нажимаешь заказать. В этот момент браузер шлет HTTP сообщение серверу. В этом сообщении указан адрес, он же URL конечной точки (endpoint) на сервере, которая будет принимать этот запрос, например это может выглядеть так: merion-shop.ru/order. Так же в этом запросе есть такая штука, которая называется метод - это просто слово, которое указывает какую операцию нужно выполнить на сервере. У HTTP существует несколько методов, в зависимости от того, какое действие производится. В нашем случае, когда мы хотим что-то создать, а именно заказ, то используется метод POST. Также в запросе есть заголовки - это может быть служебная информация, или данные для авторизации, короче все что нужно серверу для корректной обработки сообщения.
И еще: если нам надо передать много данных на сервер, например, нашу почту и адрес доставки , то можно их записать в запрос в формате JSON - это называется тело сообщения.
После выполнения запроса - сервер вернет ответ. В нем тоже несколько чаcтей. Тут так же есть заголовки с такой же служебной инфой, чтобы теперь клиент правильно обработал сообщение. Так же есть тело ответа, могут передаваться какие-то запрашиваемые данные. А могут и не передаваться, если нам ничего не нужно. Сейчас нам в ответ придет айдишник заказа, чтобы мы могли его подставить во всякие ссылки для следующих запросов.
Так вот, чтобы показать успешность выполнения запроса используются трехзначные статус коды, которые присылаются в ответе.
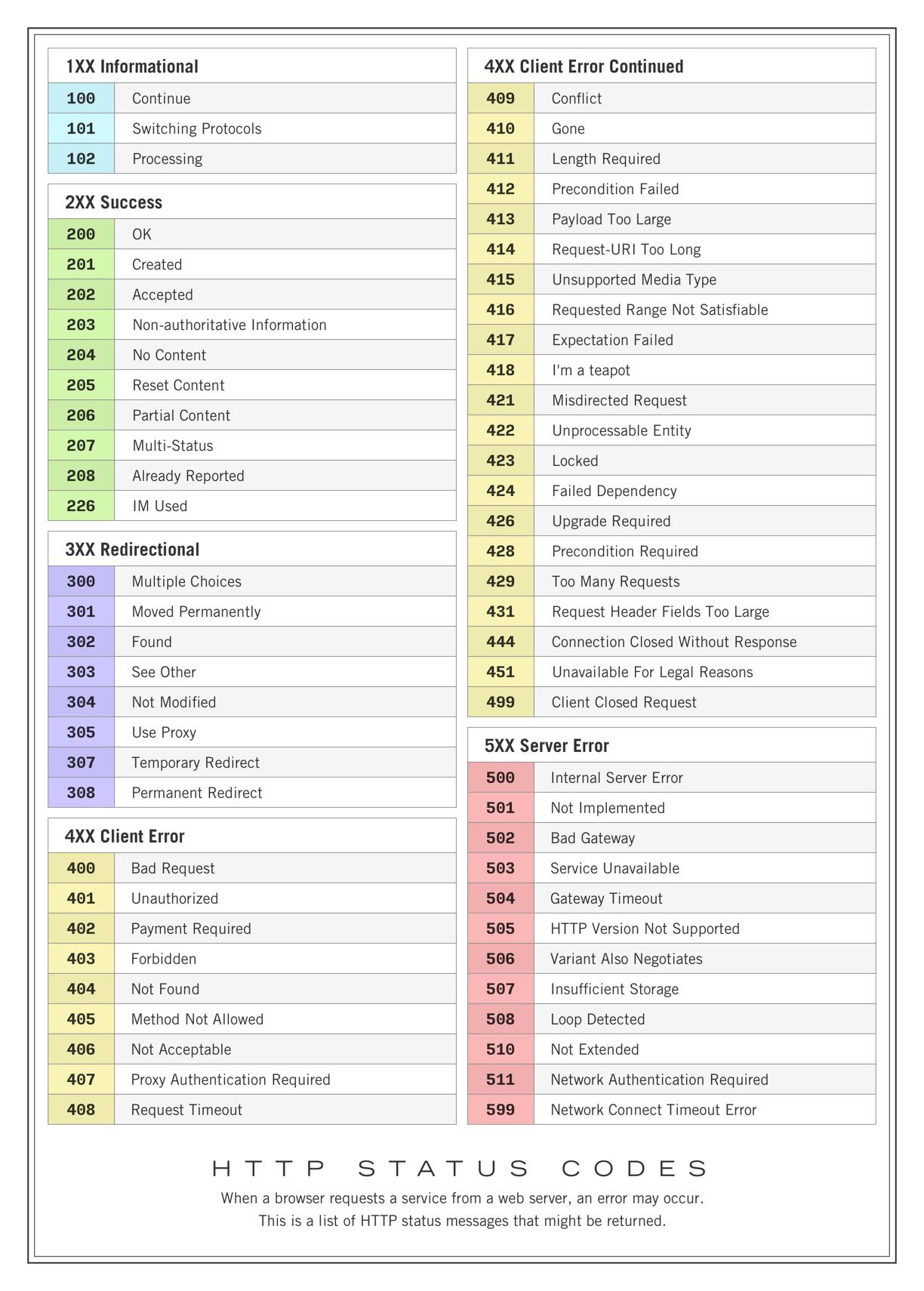
Они делятся на несколько групп - ща расскажем. Те, которые начинаются на 100 - это информационные. Например 101 ты можешь получить когда инициируется вебсокетное соединение.
Коды начинающиеся на 200 говорят о том, что запрос прошел успешно, как твое последнее свидание. Самый часто используемые это 200, который просто тебе говорит что все ОК. Если были запрошены данные, то они будут в теле ответа. 201 сигнализирует, что было созданно то, что клиент хотел создать. Как раз подходит для нашего примера - сервер скажет нам, что заказ создан при помощи этого кода. Ну и еще 204 часто можно встретить, это то же самое что и 200, но мы явно говорим что никаких данных в ответе не будет.
Коды начинающиеся на 150+150 обычно используются для редиректа страниц, например 307 - временный и 308 - постоянный редирект. Кстати, в комментах пиши сколько будет 150 + 150, если знаешь.
400е коды говорят, что на стороне клиента произошла ошибка. Например, 400 Bad request можно получить если отправил форму, но не заполнил обязательные поля, 401 Unauthorized если пытался что-то сделать, но это можно только зарегистрированным пользователям, 403 Forbidden - если если пытался что-то сделать, но лично тебе этого делать нельзя, знаменитый 404 код получишь если сервер не найдет что ты запрашиваешь - страницу или там товар, 429 если хотел задудосить сервер и делал много запросов, а 418 получишь если я чайник. Нет, серьёзно, смотри:
Ладно, допустим. Ну и 500е тоже говорят, что что-то сломалось, но уже на стороне сервера. 500 - это мы просто где-то внутри повалились, клиенту не нужно знать, что конкретно мы там криво написали - просто повалились, с кем не бывает. Ну можно и по конкретнее сказать, обычно это выдают промежуточные серверы: 503 - это сервис недоступен, 504 - превышено допустимое время обработки запроса, 502 и 504 проблемы с гейтвеем.
Вернемся к нашему примеру. Сделав заказ, ты теперь хочешь посмотреть свою корзину, так? Тут все тоже самое, только мы уже сделаем запрос с методом GET - потому что мы хотим получить данные. В ответ так же получим 200 OK, только теперь в теле уже будут данные - инфа о том, что лежит в корзине.
Кстати если мы делаем гет запрос, и нам нужно передать какие-то данные, то их уже не кладут в тело сообщения, так как это не бьется с архитектурой реста и этих ваших ресурсов - их уже указываем в параметрах пути (Path Parameters) или запроса (Query Parameters).
Выглядит это так: параметры можно непосредственно встраивать в часть пути (URL) запроса. Например вот так merion-shop.ru/catalog/{category_id} может выглядеть путь для страницы, которая возвращает список товаров определенной категории - на место category_id подставляем ее айдишник merion-shop.ru/catalog/12, а на стороне сервера вытаскиваем его и достаем из базы все товары этой категории. Тут ты как бы работаешь с сущностью каталога - с ресурсов и получаешь данные связанные с ним.
Параметры запроса же удобно использовать если мы хотим передать какие-то фильтры, опции или дополнительные данные, которые не являются частью URL. Они добавляются к концу URL после символа вопроса (?) и обычно представлены в виде пар "ключ-значение" и разделяются символом амперсанда (&) если их несколько. Например, merion-shop.ru/search?query=iphone&limit=10, где query и limit - это параметры запроса. Тут таким образом мы передаем текст поискового запроса и сколько результатов хотим получить.
Снова назад к примеру: теперь ты смотришь на заказ, и понимаешь, что ошибся с адресом. Вот тут нам понадобится метод PUT - он как пост, только не для создания чего-то, а обновления. Тут тоже мы отправим в теле данные, причем все, не только те которые изменились. И тут адрес будет примерно такой merion-shop.ru/order/12345/ где 12345 - айди нашего заказа. Обычно в ответ получаем 200 или 204 код.
А затем ты снова посмотрел на заказ, и подумал, что чето ты погорячился и пора завязывать с импульсивными покупками - и решил его отменить. Это значит, что теперь шлется сообщение с методом DELETE на тот же адрес merion-shop.ru/order/12345/ уже без тела запроса, и в ответ получаем 200 или 204 код.
В целом это все основные методы, есть еще всякие дополнительные типа PATCH, HEAD, но они редко используются.
Такие дела! Это конечно всего лишь рекомендации, никто не запрещает тебе делать GET запрос на создания и отправлять в теле JSON с данными, а в ответ возвращать 500 код с текстом “капибара”, но предупредим, это чревато получением по жопе. Потому что иначе это уже не рест, а мы тут вроде как по ресту все делаем.
Сделано это было как раз для того, чтобы все понимали что происходит и знали чего ожидать - просто все договорились, что должно быть так - этого и придерживаемся.
Ну и под конец вопрос - REST хорош, но не везде его разумно использовать. Как ты думаешь, где рест нецелесообразно использовать? А пока, как обычно шли пост запросы на лайк и комент. Пакеда!
Курс по Linux от Мерион Нетворкс - стань Linux администратором, прокачай свой скиллсет умением работать с операционными системами линукс и сделай большой шаг к DevOps