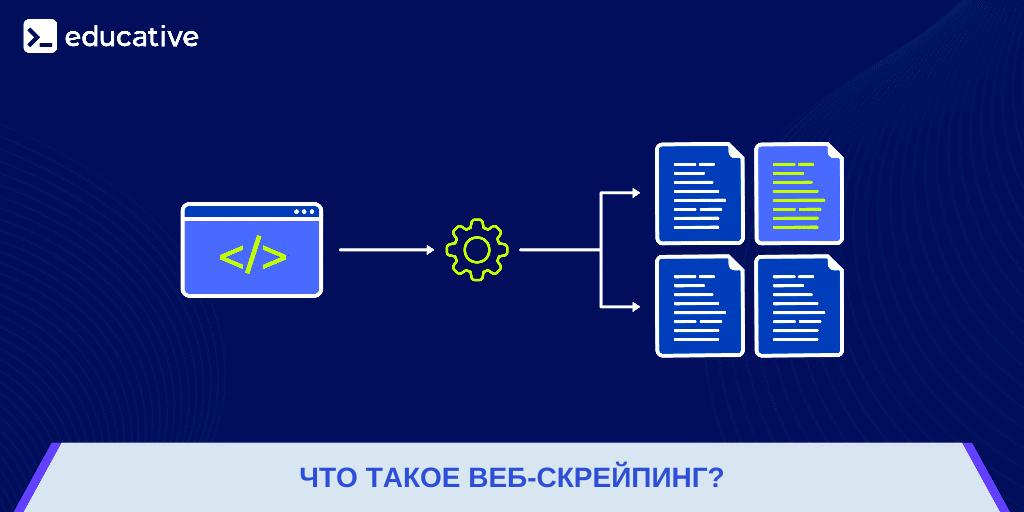
Зачастую мы работаем с веб-сайтами только потому, что нас интересует находящаяся там информация. Однако данных может быть настолько много, что их ручное извлечение может оказаться довольно продолжительным и никак не защищено от ошибок. Именно поэтому вам стоит разобраться, что же такое веб-скрейпинг. Веб-скрейпинг – это автоматическое извлечение данных с веб-сайта. Иногда его еще называют сбором веб-данных. Для этого используются специальные языки/инструменты, которые структурированно извлекают данные с веб-страниц. В дальнейшем мы можем проанализировать эти данные так, как нам нужно.
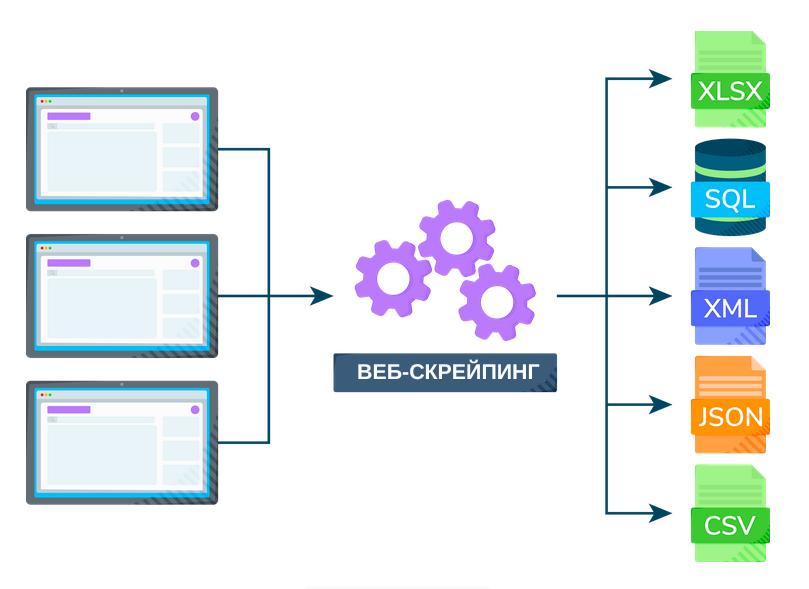
Веб-скрейпинг
Как это работает?
В большинстве случаев мы отправляем интересующему нас сайту несколько HTTP-запросов и получаем в ответ содержимое HTML этого сайта. После этого производится синтаксический анализ этого содержимого, то есть отбрасывается ненужное содержимое и сохраняются только отфильтрованные данные. При этом данные могут быть как в текстовом виде, так и в виде визуальных элементов (изображений/видео). Все это может выполнять в полуавтоматическом режиме, то есть когда мы сами копируем данные с веб-сайта, или в автоматизированном режиме, то есть когда мы используем специальные инструменты и задаем необходимые параметры извлечения данных.
Проблемы веб-скрейпинга
Если на веб-сайте отсутствует автоматическая блокировка ботов, например, капча, то его содержимое можно легко скопировать с помощью автоматизированных инструментов. На результат извлечения также влияет разновидность капчи, реализованной на сайте – текстовая, графическая, звуковая, логическая, поведенческая или даже невидимая. Однако некоторые веб-сайты теперь предлагают решения для расшифровки этих капч от вашего имени, например, 2Captcha или Anti-CAPTCHA, которые, как правило, не бесплатны. Или же, если вы хотите избежать таких расходов, можете воспользоваться методами машинного обучения, которые могут за вас решить текстовые и графические капчи.
Законность веб-скрейпинга
В целом веб-скрейпинг не является чем-то противозаконным. Однако проблемы могут начаться тогда, когда вы получаете информацию с веб-сайта, не предназначенную для публичного ознакомления. Как правило, данные, представленные на сайте, который не требует входа в систему с помощью учетных данных, можно спокойно извлечь с помощью скрейпера и не бояться каких-то серьезных проблем. Но если на сайте установлено специальное программное обеспечение, которое ограничивает использование веб-скрейперов, вам следует избегать таких действий.
Как работают веб-скрейперы?
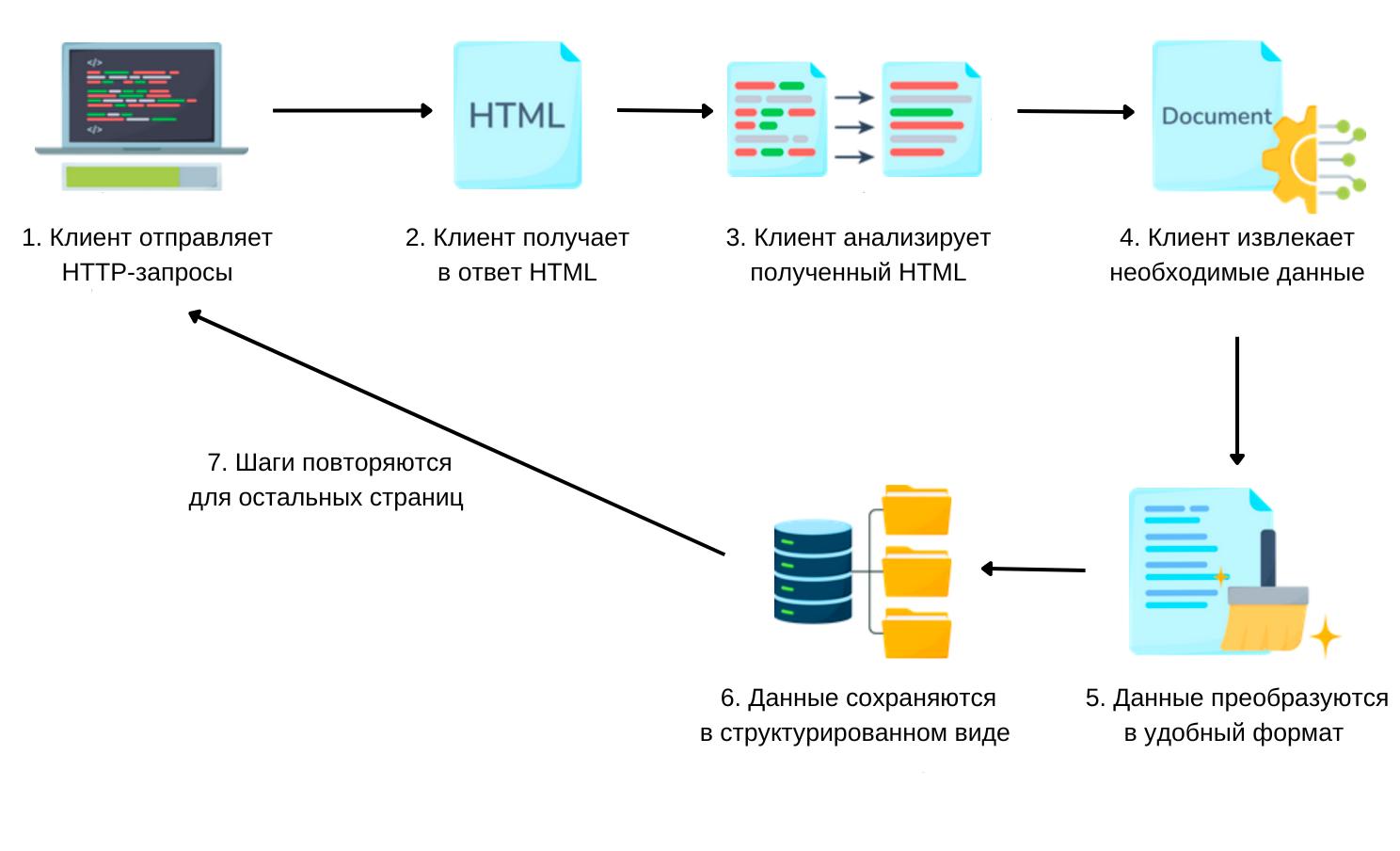
Существует множество разных веб-скрейперов, и каждый из них оснащен своим особым набором функций. Ниже в общих чертах описан принцип работы обычного веб-скрейпера:
- HTTP-запросы. Веб-скрейпер начинает с отправки HTTP-запроса на указанный URL-адрес с целью получить содержимое веб-страницы. Эта процедура идентична тому, как веб-браузер обращается к веб-страницам.
- Получение HTML. Сервер, на котором размещен веб-сайт, отвечает на запрос, отправляя HTML-содержимое веб-страницы. Этот HTML-код содержит все элементы (текст, изображения, ссылки и прочие элементы, составляющие веб-страницу).
- Синтаксический анализ HTML. Дальше веб-скрейпер приступает к синтаксическому анализу HTML. Он анализирует и интерпретирует HTML-содержимое, чтобы найти те разделы страницы, где содержатся нужные данные. Это предполагает использование таких инструментов, как библиотеки синтаксического анализа HTML, которые помогают перемещаться по структурным элементам HTML-кода.
- Извлечение данных. После того, как подходящие фрагменты HTML определены, скрейпер переходит к извлечению интересующих нас данных. Это может быть любая категория содержимого, в том числе текст, изображения, ссылки, таблицы и прочая информация, найденная на веб-странице.
- Очистка данных. В зависимости от качества HTML-кода и структуры страницы, может потребовать та или иная форма очистки и форматирования извлеченных данных. Сюда относится удаление лишних тегов и специальных символов. Этот этап гарантирует, что данные отформатированы и пригодны для дальнейшего использования.
- Запись данных. После того, как данные будут очищены, их необходимо организовать в структурированный формат. Для этого могут использоваться CSV-файлы, базы данных или какие-то другие решения для хранения данных, отвечающие намеченной цели.
- Обход страниц. В ситуациях, когда скрейперу необходимо собрать данные с нескольких страниц (например, при извлечении результатов поиска), он выполняет этот процесс итеративно, отправляя запросы на отдельные URL-адреса и извлекая, таким образом, данные с каждой страницы отдельно.
- Обработки динамического содержимого. Данные с веб-сайтов, которые используют JavaScript для загрузки динамического содержимого, требуют более сложных методов очистки после первоначального получения HTML. Это предполагает использование таких инструментов, как консольный браузер, или таких ресурсов, как Selenium, для того, чтобы скрейпер мог взаимодействовать со страницей как обычный пользователь, тем самым извлекая динамически загружаемое содержимое.
- Изучение robots.txt. Скрейпер должен придерживаться инструкциям, изложенным в файле сайта под названием robots.txt. В нем прописано, какие разделы можно извлекать, а какие нельзя. Соблюдение этих требований позволит вам избежать юридических и этических проблем.
- Ограничение скорости. Для того, чтобы не перегружать сервер веб-сайта огромным количеством запросов за короткий промежуток времени, скрейпер может внедрить специальные механизмы ограничения скорости. Эти механизмы предназначены для того, чтобы извлекать данные разумно и умеренно.
Стандартные этапы веб-скрейпинга
Не стоит забывать, что веб-скрейпинг должен выполняться сознательно и с соблюдением всех этических норм. Прежде чем приступать к извлечению данных с веб-сайта, рекомендуется внимательно изучить условия его использования. В таком случае вы соблюдете все правила скрейпинга и будете знать о любых ограничениях или правилах, предусмотренных администраторами веб-сайта.
Как извлечь данные с веб-сайта с помощью Python?
А теперь давайте научимся извлекать данные с веб-сайта с помощью Python. В качестве примера мы будем использовать вот этот блог о преимуществах и применении GraphQL.
Многие современные веб-сайты имеют довольно сложную структуру HTML. Благо, большая часть веб-браузеров предлагает специальные инструменты, которые могут помочь разобраться в ней. Например, если мы откроем этот блог через Chrome, то можем щелкнуть правой кнопкой мыши на любой заголовок и выбрать в меню пункт «Inspect» (Посмотреть код) (см. ниже):
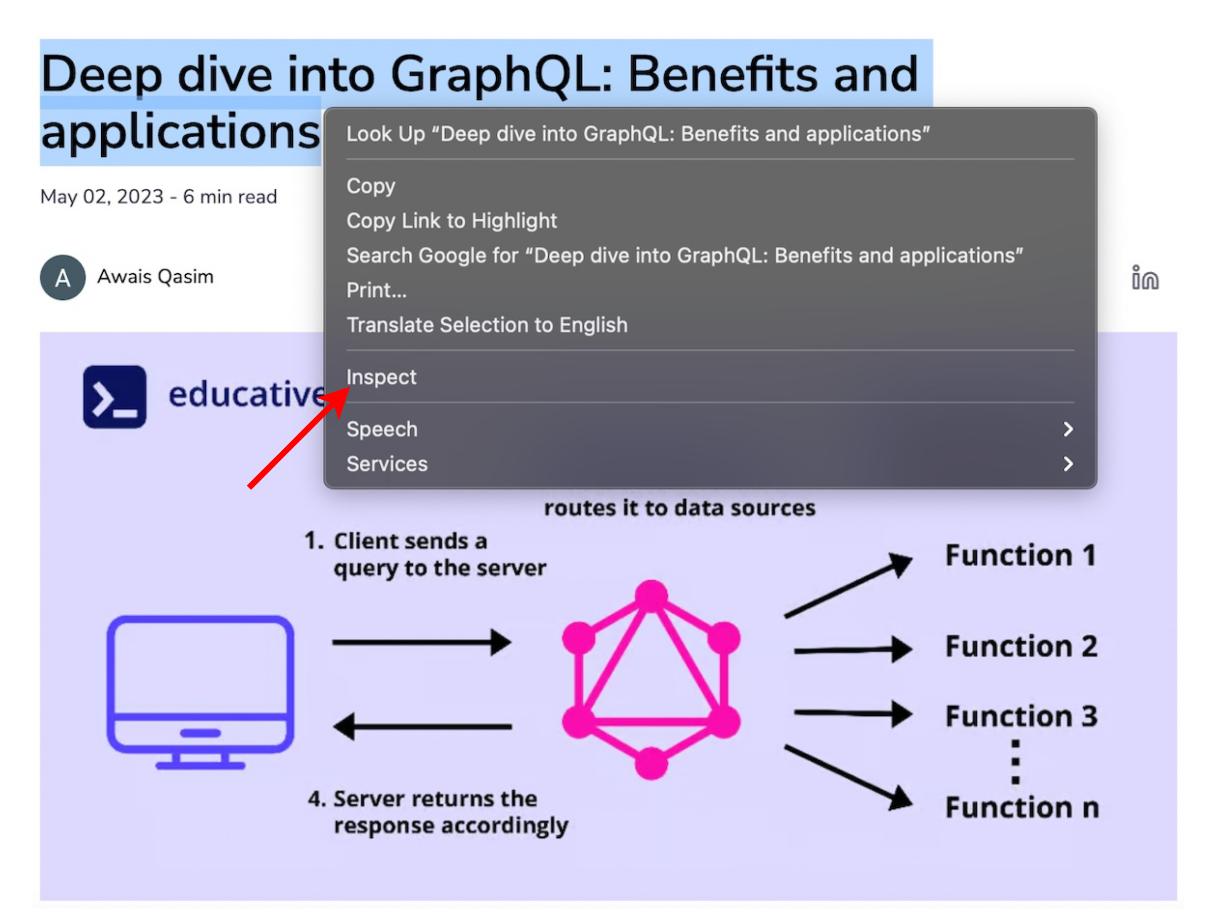
Щелчок правой кнопкой мыши по блогу, информацию с которого мы хотим извлечь
После того, как мы нажмем «Inspect», перед нами появится боковая панель, на которой отмечен HTML-тег, содержащий этот текст.
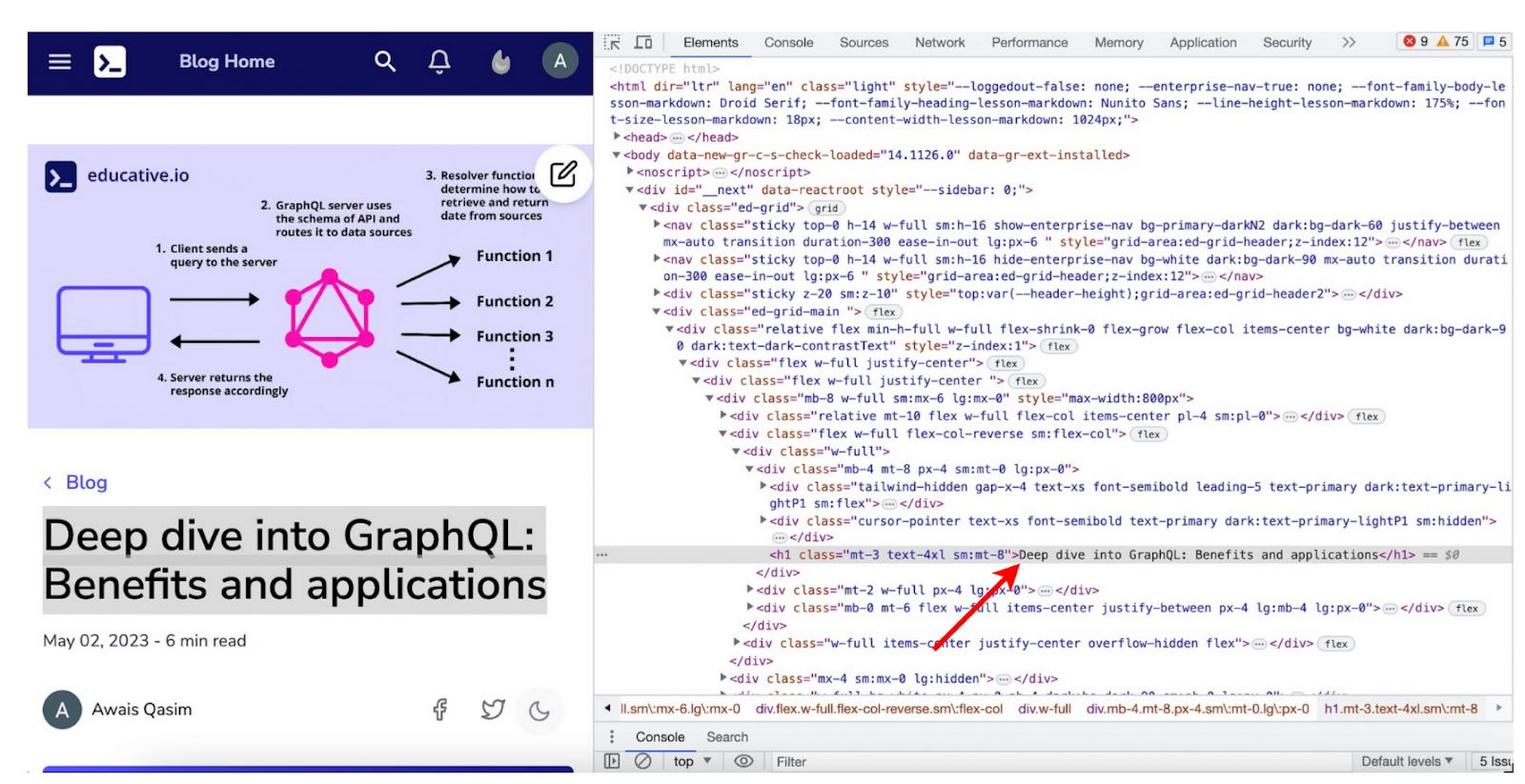
Обнаружение тега текста, который мы хотим проанализировать
В Python и других языка программирования доступен целый ряд различных веб-скрейперов. Но в данном случае мы будем использовать довольно известный веб-скрейпер Beautiful Soup. Настроить его можно, выполнив следующую команду:
pip3 install beautifulsoup4
Извлечение заголовка H1 с веб-сайта
Давайте напишем код, который будет извлекать все заголовки H1 из нашего блога.
import requests
from bs4 import BeautifulSoup
url = 'https://www.educative.io/blog/get-started-with-python-debuggers'
def get_data():
req = requests.get(url)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
data_stream = soup.findAll('h1')
for data_chunk in data_stream:
print(data_chunk)
print("\n")
return data_stream
if __name__ == '__main__':
data = get_data()
Извлечение всех заголовков Н1
Если вы выполним код, приведенный выше, то получим следующий ответ.

Печать заголовков Н1, полученных из блога
А теперь давайте разберем наш код.
Строки 1-2. Мы импортируем скрейпер, который будем использовать, т.е. BeautifulSoup.
Строка 4. Мы указываем URL-адрес блога, с которого будем извлекать данные.
Строка 6. Мы определяем метод get_data().
Строка 8. С помощью URL-адреса мы создаем объект req.
Строки 9-10. Мы указываем анализатор HTML, в нашем случае это html.parser. Он включен в сам Python. Но мы также можем использовать любой другой анализатор.
Строка 11. Мы указываем тег, который хотим получить, т.е. h1.
Строки 13-15. Мы печатаем все данные, которые получаем с сайта по указанному нами тегу.
Строка 17. Возвращаем полученные данные.
А теперь давайте изменим код так, чтобы получить все заголовки h2. Для этого заменим в 11-ой строке кода тег h1 на h2, как показано ниже.
data_stream = soup.findAll('h2')
Извлечение всех заголовков H2
Теперь, когда мы выполним код, мы увидим, что напечатались все заголовки h2.
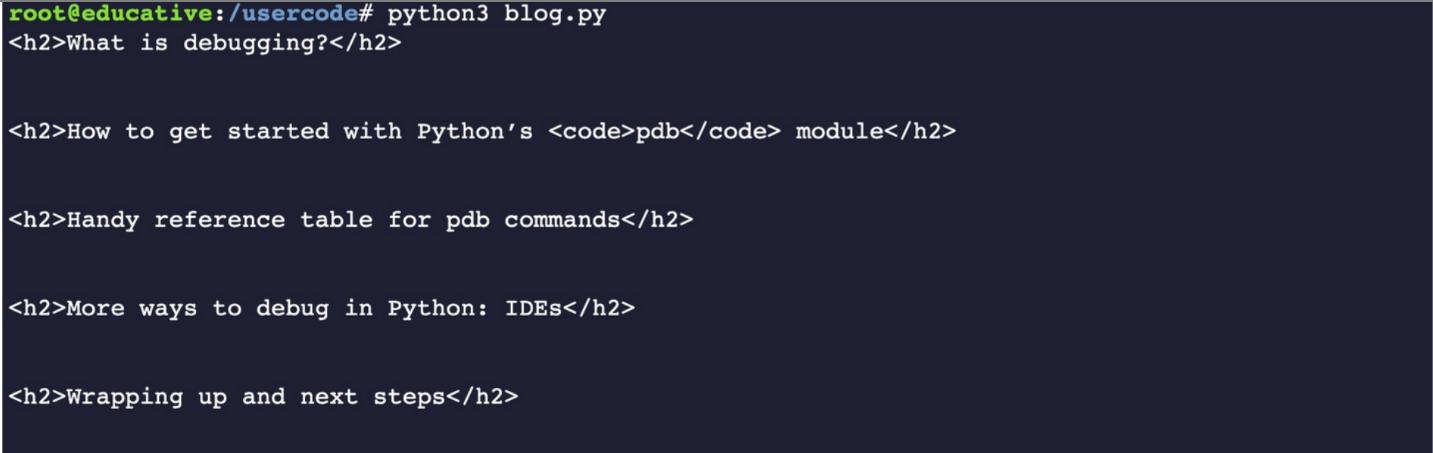
Печать заголовков Н2, полученных из блога
И напоследок, давайте напишем код, который позволит нам получить все абзацы блога. Если мы снова воспользуемся функцией «Inspect», как мы делали это ранее, то увидим, что абзацы заключены в тег <p>. Так что на этот раз мы будем использовать в 11-ой строке кода тег p , как показано ниже.
data_stream = soup.findAll('p')
Извлечение всех абзацев
Выполнив этот код, мы получим все абзацы блога.
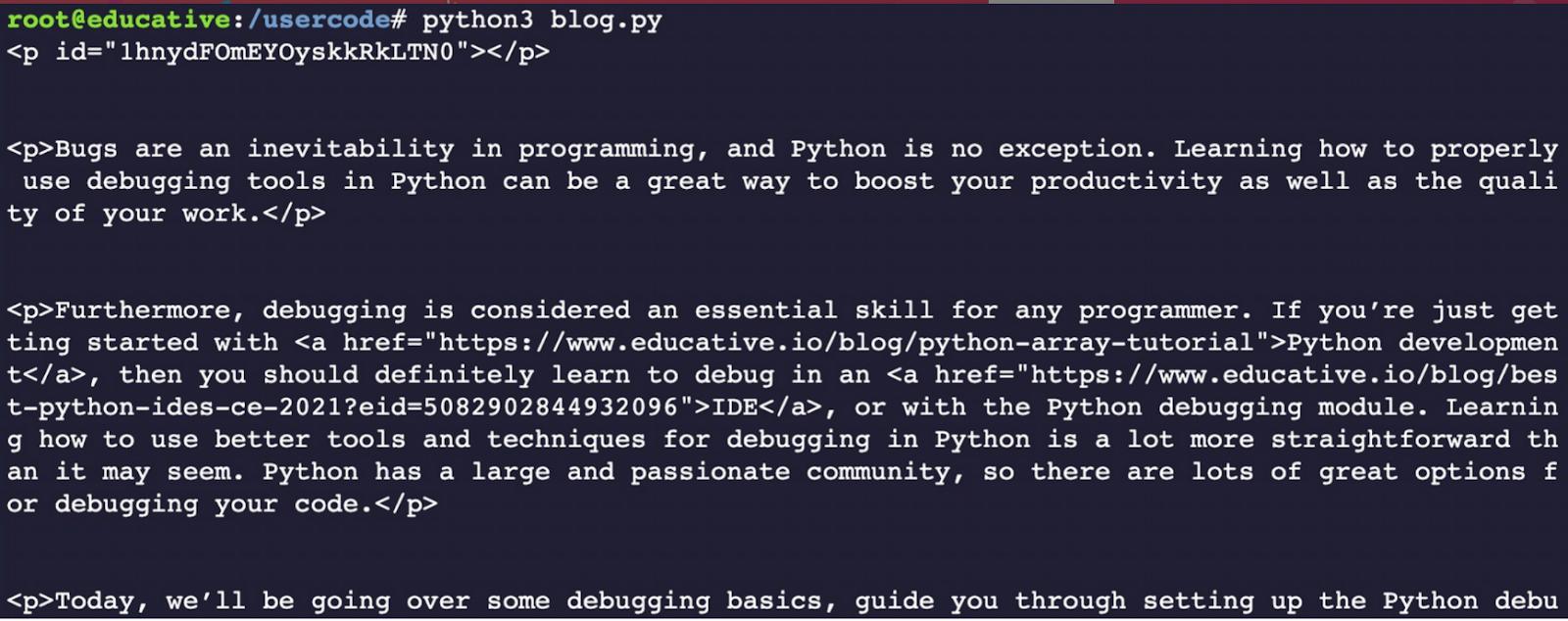
Печать абзацов, полученных из блога
На этой ноте мы завершаем наш рассказ о том, что такое веб-скрейпинг и как им пользоваться. Мы начали с того, что из себя представляет веб-скрейпинг и чем он полезен. Далее мы обсудили некоторые юридические вопросы, с которыми вы можете столкнуться. Затем мы обсудили, как веб-скрейперы работают в целом. После чего мы реализовали вполне работающий веб-скрейпер на практике с помощью Python. Конечно, существует огромное количество инструментов, которыми вы можете воспользоваться, но никогда не будет лишним знать в общих чертах, как работают веб-скрейперы.