Что такое индексы баз данных?
Индекс базы данных – это дополнительная структура данных, которая создается наряду с данными в таблице. Вы определяете индекс для таблицы и столбца (или набора столбцов). Таким образом вы создаете новую структуру поиска данных, которая непосредственно связана с этой таблицей и набором столбцов.
В этой статье мы подробно распишем, что такое индекс, как его можно создать, какие есть типы индексов и когда их нужно использовать.
Для чего нужны индексы?
Индексы баз данных ускоряют процесс извлечения данных, и тем самым повышают производительность запросов. Это и есть главная задача таких индексов. Все это происходит за счет того, что для хранения b-дерева и указателей на фактические данные выделяется дополнительная память.
Индексы используются для того, чтобы при каждом запросе строки из таблицы у базы данных не было необходимости просматривать все строки. В общем-то, индексы обеспечивают довольно эффективный способ обращения к упорядоченным записям.
Как можно создать индекс?
У разных РСУБД разный синтаксис для создания индекса. Помимо этого, разные механизмы СУБД используют для этого разные параметры. Это мы с вами сможем увидеть чуть позже. И тем не менее, все же существует общий синтаксис создания самого примитивного индекса, который подходит для всех механизмов СУБД. Ниже приведена синтаксическая структура, с помощью которой можно создать в таблице самый примитивный индекс.
CREATE INDEX index_name
ON table_name (column_name_1, column_name_2, …)
А сейчас давайте воспользуемся этой структурой, чтобы создать индекс для реальной таблицы. Допустим, у нас есть таблица Customer (см. ниже), и мы хотим создать индекс для того, чтобы ускорить процесс поиска по имени клиента.
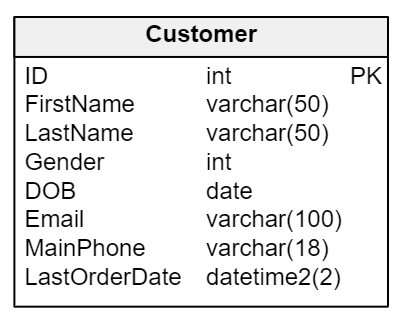
CREATE INDEX IX_CustomerName
ON Customer (FirstName, LastName)
После того, как мы запустим этот код, мы получим индекс для таблицы Customer под названием IX_CustomerName. За счет этого индекса поиск данных в столбцах FirstName и LastName будет проходить куда быстрее.
Индекс, который создается, что называется, за кадром, еще называют некластеризованным индексом или индексом бинарного поиска. С помощью этого индекса мы можем выполнять оптимизированные запросы для сценариев, где присутствуют такие запросы, как:
SELECT FirstName, LastName, Email
FROM Customer
WHERE FirstName = ‘Mark’ and LastName = ‘Thompson’
Как показывает опыт, каждый раз, когда мы хотим оптимизировать запрос, мы смотрим на столбцы, которые используются для выборки данных, и проверяем, есть ли у нас для них индекс. В случае, если столбцы в предложении SELECT аналогичны столбцам в предложениях для выборки данных, у нас появляется оптимизированный план действий, и, соответственно, поиск проходит быстрее.
Но это не то, что нам нужно. Индексирование – это гораздо большее, чем просто эти правила.
Какие бывают индексы в SQL?
Раз уж мы разобрались, как создавать индекс, теперь давайте обсудим основные типы индексов реляционных баз данных, с помощью которых вы сможете оптимизировать свои запросы. Для некоторых из них нужен определенный механизм СУБД, поэтому мы укажем, где их можно использовать.
Все индексы хранят указатели на строки данных в структуре данных под названием дерево поиска. Эта структура оптимизирована для поиска, и она же является главной опорой для индекса. С ее помощью мы можем выполнять что-то наподобие поиска в двоичном дереве поиска, но в нашем случае все немного сложнее.
Есть много различных индексов. У каждого из них своя внутренняя структура данных, а, соответственно, и назначение. Дальше мы рассмотрим их более подробно, а здесь пока кратко оговорим их названия.
- С точки зрения характеристик атрибута:
- Первичный индекс
- Кластеризованный индекс
- Вторичный индекс
- С точки зрения количества ссылок на файл данных:
- Плотный индекс
- Разреженный индекс
- Нестандартные индексы для очень специфичных сценариев:
- Битовый индекс
- Реверсивный индекс
- Хэш-индекс
- Отфильтрованный индекс
- Индекс по функции
- Пространственный индекс
Давайте для примера воспользуемся той же таблицей Customer, что мы использовали ранее. Для того, чтобы понять, как выглядят выборочные данные, давайте напишем простой запрос SELECT и вернем из таблицы все данные.
Кластеризованный индекс
Кластеризованный (или кластеризующий) индекс – это один из самых распространенных индексов, которые можно использовать во всех современных полнофункциональных СУБД. Этот индекс определяет порядок, в котором данные хранятся на странице (физически) и в таблице (неявно).
Давайте посмотрим на пример. Допустим, что первые две строки находятся на Странице №1, третья и четвертая строки – на Странице №2, а последняя пятая строка – на Странице №3 (см. ниже).

Задача кластеризованного индекса – физически хранить строки в порядке возрастания или убывания, беря в качестве основы столбец, который был выбран. Этот индекс нужен для того, чтобы хранить именно отсортированные данные. Это значительно упрощает поиск одного или нескольких значений в каком-нибудь диапазоне. Правда, кластеризованный индекс может помочь нам только в том случае, если мы ищем значения в каком-то диапазоне, а не среди всех данных.
Допустим, что список клиентов на нашей информационной панели всегда отображается по алфавиту. Так вот, мы хотим, чтобы наши данные хранились в нашей базе данных в отсортированном порядке по именам и фамилиям. И для того, чтобы создать кластеризованный индекс, мы пишем следующий запрос:
CREATE CLUSTERED INDEX CI_FirstName_LastName
ON Customer (FirstName ASC, LastName ASC);
Этот запрос сказывается на предыдущем, с помощью которого мы вернули все данные. Когда мы создали кластеризованный индекс с сортировкой по возрастанию по имени и фамилии, то мы физически переупорядочили данные на страницах. Если мы с вами взглянем на наши страницы, то увидим, что теперь они выглядят иначе:

Как мы видим, теперь данные отсортированы по имени, а потом по фамилии. Это может существенно упростить нам жизнь и улучшить производительность, так как, если мы сделаем запрос на сортировку строк по алфавиту, ничего не произойдет, поскольку строки и так хранятся в отсортированном порядке. Таким образом, мы можем обойтись без сортировки в самом запросе.
Если мы захотим получить данные о первых 10 клиентах с точки зрения алфавитного порядка, то база данных не будет искать их по всей таблице. Она просто вернет страницы с первыми 10 записями, так как они уже отсортированы.
Битовый индекс
Битовый индекс – это еще одна разновидность индексов. На момент написания статьи его можно было использовать только в Oracle. Этот индекс особо полезен в одном конкретном сценарии, когда вы хотите запросить и отфильтровать по столбцу какую-то часть таблицы, которая в сравнении со всей таблицей не такая уж большая.
Давайте вернемся к нашему примеру и попробуем применить этот битовый индекс. Представьте, что в нашей таблице Customer на самом деле не 5, а более 10 миллионов строк. И, допустим, мы хотим отфильтровать наш запрос, в результате которого мы получим данные о клиентах женского пола с фамилией Watson.

Мы можем написать запрос примерно вот так:
SELECT FirstName, LastName, Email
FROM Customer
WHERE Gender = 2 AND LastNamr = “Watson”;
Битовый индекс идеально подходит для этой ситуации, так как в сравнении с 10 миллионами записями строк, которые соответствуют какому-то определенному полу, гораздо меньше. Теперь ускорим наш запрос, создав битовый индекс:
CREATE BIMAP INDEX BMP_Gender
ON Customer (Gender)
А теперь мы выбираем «Kate Watson» и ее адрес электронной почты (см. ниже), а также все остальные подходящие строки из 10 миллионов в этой таблице.

Битовый индекс может оказаться еще более мощным, если вы создадите его в предложении JOIN. Например, если мы соединим две таблицы: Customer и Sales, и отфильтруем их по полу. В этом случае битовый индекс будет выглядеть примерно так:
CREATE BITMAP INDEX BMP_Gender_Sales
ON Customer (Gender)
FROM Customer, Sales
WHERE Customer.ID = Sales.Customer_ID;
Каждый раз, когда вы будете отправлять запрос на объединение этих двух таблиц и их фильтрации по полу, вы будете очень близки к максимальной производительности запроса.
Реверсивный индекс
Реверсивный индекс во многом похож на обычный индекс. Но он не создает двоичное дерево поиска для того, чтобы ускорить поиск данных в порядке возрастания, этот индекс оптимизирован для поиска данных в порядке убывания. Синтаксическая конструкция для создания реверсивного индекса очень похожа на синтаксическую конструкцию обычного некластеризованного индекса. Разница лишь в том, что мы должны указать, что данные должны быть в обратном (убывающем) порядке.
Предположим, что мы хотим оптимизировать запрос, с помощью которого хотим узнать имена клиентов, которые разместили 3 последних заказа. Создадим индекс:
CREATE INDEX IX_LastOrder_Customer
ON Customer (LastOrder DESC);
Самое важное слово в этой конструкции – это DESC. Оно сообщает механизму СУБД, что необходимо создать именно реверсивный индекс. Таким образом, каждый раз, когда мы будем запрашивать данные о трех последних заказах из таблицы Customer, мы будем получать наилучшую производительность запроса.
Какую структуру данных использует индекс?
Как мы уже упоминали, индексы создаются наряду с другими структурами данных для оптимизации операций поиска. Но что это за структуры данных?
Сбалансированное дерево
Самые распространенные индексы для того, чтобы ускорить запросы, используют, так сказать, за кадром сбалансированное дерево. Большинство механизмов СУБД используют либо сбалансированное дерево, либо его разновидность, например, b+-дерево. Ниже показано как выглядит структура обычного сбалансированного дерева.
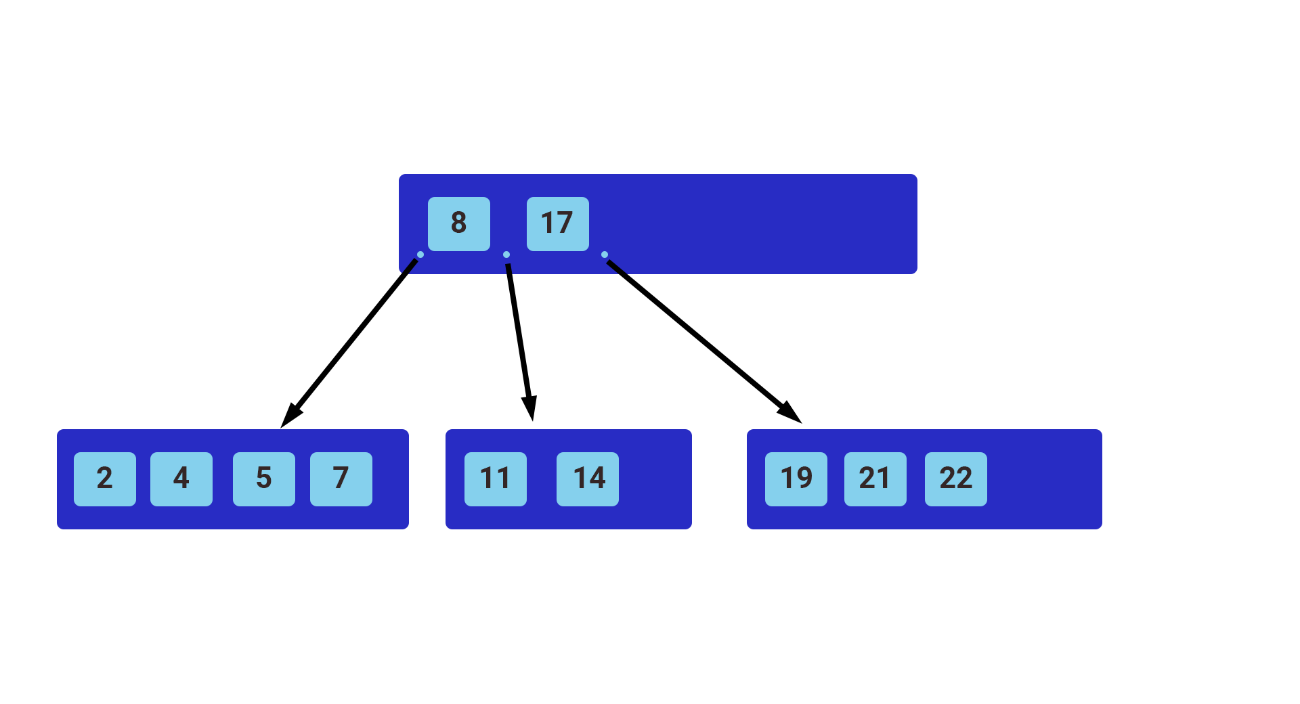
Верхний узел – это корневой, а все остальные, которые расположены ниже, - это либо дочерние, либо конечные узлы. Поиск строки начинается с корневого узла. Мы сравниваем искомое значение со значением в текущем узле, больше оно или меньше. В зависимости от результата этого сравнения мы поймем, в какую сторону нам нужно идти, влево или вправо. Если мы посмотрим на пример выше, то увидим, что все значения меньше 8 ведут нас влево, а значения больше 8 – вправо, и т.д.
Хэш
Хэш используется хэш-индексами. Это структура данных, которая обеспечивает один из самых быстрых поисков. С помощью хэша индексы могут очень быстро находить данные, которые хранятся в таблице.
Основная идея хэша состоит в следующем: вместо того, чтобы перебирать все ключи поиска с помощью индексов или искать их по всей таблице, мы применяем к нему хэш-функцию. Этот ключ поиска преобразуется в хэш-значение, которое определяет соответствующе, так называемое, «ведро». Давайте посмотрим на пример ниже. В нем мы применяем хэш-функцию к ключу поиска «Mike», после чего оно ставит в соответствие определенное ведро.
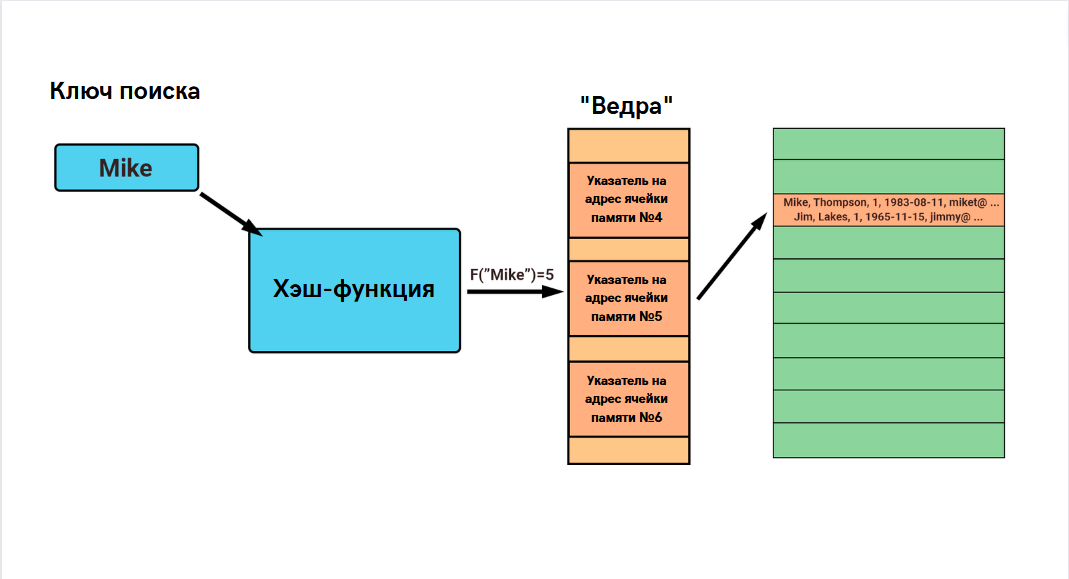
Каждое такое ведро в массиве ведер содержит одинаковое количество записей. Неважно, сколько в столбце различных значений, каждая строка сопоставляется с отдельным ведром. После чего выбирается соответствующая строка и возвращается из этого ведра.
Реализация индексов с помощью механизмов РСУБД
Как вы уже могли понять, в реляционной базе данных есть несколько типов индексов. И у каждого механизма СУБД есть свои собственные реализации этих индексов. Давайте пройдемся по самым популярным механизмам СУБД, перечислим индексы, которые у них есть и обсудим, когда их лучше использовать.
Индексы в PostgreSQL
У PostgreSQL список индексов довольно большой. Каждый из них подходит для конкретных сценариев:
- Самый распространенный индекс – индекс В-дерева. Он будет полезен в ситуациях, когда вам нужно сравнивать диапазоны в столбцах, которые можно сортировать.
- Хэш-индекс хранит 32-битный хэш-код, который является производным от значений индексированных столбцов. Он будет полезен в тех случаях, когда вам нужно проводить простые сравнения.
- GiST – это не один какой-то индекс, а скорее логическая структура, в которой могут быть реализованы несколько разных стратегий индексирования. Чаще всего эта структура используется в сценариях, в рамках которых вам нужно найти «ближайшего соседа» в геометрических типах данных.
- SP-GiST, как и GiST, реализует несколько стратегий индексирования. В его основе лежат различные структуры данных, такие как деревья квадрантов, k-мерные и базисные деревья. Этот индекс используется в тех же сценариях, что и GiST.
- GIN также называют «инвертированным индексом». Он используется в сценариях, в которых данные являются массивом. Инвертированный индекс содержит отдельную запись для каждого компонента массива.
- BRIN расшифровывается как «Block Range INdex», что переводится как «блочно-диапазонный индекс». Он используется для хранения краткого описания значений на последовательных страницах физических данных внутри таблицы. Лучше всего он подходит для ситуаций, когда значения в строках перекликаются с физическим порядком страниц данных.
Индексы в Oracle
У Oracle список индексов чуть меньше. Но при этом они считаются более продуманными с точки зрения применимости.
- В-дерево – это стандартный индекс. Он также есть и в других механизмах СУБД. В-дерево лучше всего подходит для представления первичных ключей и столбцов, у которых огромное количество различных значений относительно общего числа строк.
- Битовый индекс нужен для обратных сценариев. Например, его можно использовать в сценариях, где количество различных значений в столбце не так велико относительно общего числа строк.
-
Индекс по функции – это индекс, в рамках которого значение, хранящееся в дереве поиска, определяется функцией. Таким образом он обеспечивает отличную производительность запросов, в которых есть предложения WHERE с функциями внутри.
Индексы в SQL Server
У SQL Server не так много индексов, но при этом у них очень много функциональных возможностей.
- Кластеризованный индекс нужен не только для того, чтобы механизм СУБД мог выполнить поиск в запросе. Он физически реорганизовывает строки на страницах данных так, чтобы они были отсортированы либо по возрастанию, либо по убыванию.
- Некластеризованный индекс – это эквивалент В-дерева, которое есть в других механизмах СУБД. В основном он хорошо подходит для ситуаций, когда нужно перебрать данные с огромным количеством различных значений.
-
Отфильтрованные индексы создаются для определенных групп данных. Они используются для того, чтобы оптимизировать поиск ассиметричных данных с заданными критериями. Например, мы хотим найти в столбце число 55. Но оно есть лишь в нескольких строках (относительно общего числа строк в таблице). Тогда вы можете создать отфильтрованный индекс по принципу кластеризованного, просто дополнительно указав условие WHERE column = 55.
Индексы в MySQL
В MySQL тоже есть несколько индексов, с помощью которых можно повысить производительность запросов.
-
Индекс первичного ключа – это уникальный индекс, с помощью которого можно быстро и эффективно обращаться к уникальным значениям. Также для него выгодной является оптимизация NOT NULL, так как у него не может быть значения NULL. Он всегда используется при определении первичного ключа и создается автоматически, когда вы указываете ключевые слова PRIMARY KEY.
-
Однозначный индекс во многом похож на индекс первичного ключа. Но он более гибкий в том смысле, что он позволяет многократно сохранять значения NULL. Он используется для того, чтобы обеспечить дополнительную уникальность в том случае, когда первичный ключ уже был создан.
Расширьте свой инструментарий с помощью индексов баз данных
Если вы дошли аж до сюда, то значит, вам понравилось читать про индексы баз данных! Я надеюсь, что эта информация была для вас полезной, и вы смогли найти здесь для себя что-то новое. Если вдруг ваши запросы начнут тормозить, то с помощью ваших знаний о том, какие есть индексы в различных механизмах СУБД, вы сможете повысить производительность запросов.
Иногда может быть так, что обычного В-дерева будет недостаточно, или он может не соответствовать схеме и/или данным. Поэтому иметь представление о том, какие еще есть типы индексов в реляционной базе данных, это все равно что иметь швейцарский армейский нож в своем ящике с инструментами.
