Справка
Сетевые стандарты – это набор правил, которые реализует браузер. Они определяют и описывают составляющие Всемирной паутины.
W3C – это международное сообщество, которое занимается разработкой открытых стандартов для Интернета. Они следят за тем, чтобы все придерживались одних и тех же рекомендаций, вследствие чего пропадет необходимость поддерживать десятки совершенно разных сред.
Современный браузер – это достаточно мудрёное программное обеспечение с кодовой базой, которая состоит из десятка миллионов строк кода. И потому его, как правило, разбивают на несколько модулей, каждый из которых отвечает за разную логику.
Две самых важных части браузера – это движок JavaScript и механизм визуализации.
Blink - это механизм визуализации, который отвечает за весь конвейер визуализации, в том числе DOM-деревья, стили, события, интеграцию с V8. Он анализирует DOM-дерево, задает стили и определяет наглядную геометрию всех элементов.
Blink расцвечивает содержимое на вашем экране, постоянно отслеживая динамические изменения при помощи кадров анимации. Движок JS – это большая часть браузера, но мы еще эту тему не разбирали.
Движок JavaScript 101
Движок JavaScript выполняет и компилирует код JavaScript в собственный машинный код. У каждого крупного браузера есть свой собственный разработанный движок JS: Google Chrome использует V8, Safari – JavaScriptCore, а Firefox – SpiderMonkey.
Мы будем работать исключительно с V8, так как он используется в Node.js и Electron, но при этом нужно понимать, что другие движки построены аналогично.
На каждом этапе будет присутствовать ссылка на код, ответственный за этот конкретный этап, чтобы у вас была возможность ознакомиться с кодовой базой и продолжить работу за рамками данной статьи.
Мы будем работать с зеркалом (зеркальным сервером) V8 на GitHub. Оно предоставляет удобный и хорошо знакомый пользовательский интерфейс для навигации по кодовой базе.
Подготовка исходного кода
Для начала V8 должен загрузить исходный код. Это можно сделать через сеть, из кэша или в этом вам может помочь квалифицированный работник.
После того, как вы получите код, нам необходимо изменить его так, чтобы его смог понять компилятор. Этот процесс называется синтаксическим анализом. В нем участвуют два компонента: сканер и сам синтаксический анализатор.
Сканер берет файл JS и конвертирует его в список известных токенов. Список всех токенов JS есть в файле keywords.txt.
Синтаксический анализатор берет этот список и формирует дерево абстрактного синтаксического анализа (AST – Abstract Syntax Tree). AST – это древовидное представление исходного кода. Каждый узел дерева – это конструкция, которая встречается в коде.
Давайте посмотрим на простой пример:
function foo() {
let bar = 1;
return bar;
}
Этот код образует следующее дерево:
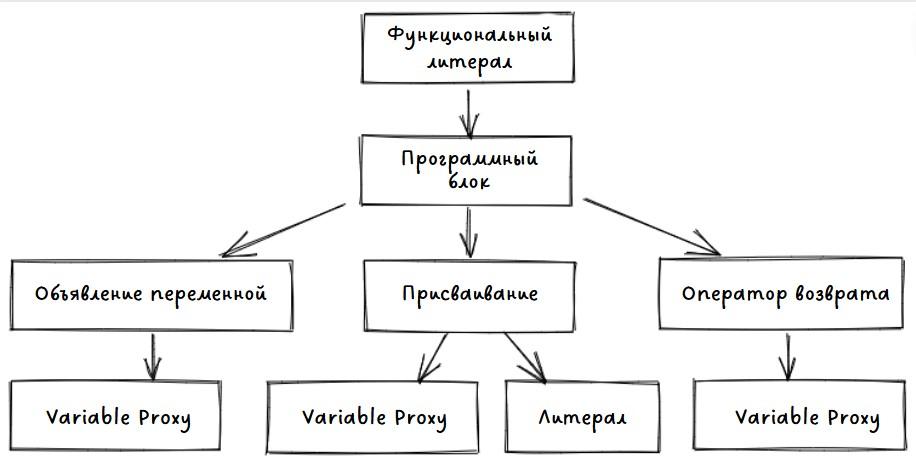
Пример AST-дерева
Вы можете выполнить этот код, выполнив обход дерева в ширину (корень, левая ветка, правая ветка):
-
Определите функцию foo.
-
Объявите переменную bar.
-
Присвойте значение 1 переменной bar.
-
Верните переменную bar как результат работы функции.
Вы также увидите VariableProxy. Это элемент, который связывает абстрактную переменную с местом в памяти. Процесс разрешения VariableProxy называется анализом области видимости переменных.
В нашем примере в качестве результата мы получим все VariableProxy, которые указывают на одну и ту же переменную bar.
JIT-парадигма
Согласно общим правилам, для того, чтобы выполнить код, язык программирования нужно преобразовать в машинный код. Есть несколько способов, как это можно сделать.
Самый распространённый способ преобразования кода – это компиляция перед выполнением. Работает это так же, как и звучит: код преобразуется в машинный непосредственно перед выполнением программы на этапе компиляции.
Такой подход используют многие языки программирования, например, C++, Java и другие.
С другой стороны, у нас есть интерпретирование: каждая строка кода выполняется непосредственно по время выполнения программы. Такой подход, как правило, используют языки с динамической типизацией, например, JavaScript и Python, так как до выполнения точный тип данных неизвестен.
Так как компиляция перед выполнением позволяет оценить весь код сразу, она может обеспечить лучшую оптимизацию, а, соответственно, и получить более производительный код. Но при этом интерпретирование проще с точки зрения реализации, но, как правило, медленнее, чем вариант с компиляцией.
Для того, чтобы быстрее и эффективнее преобразовывать код, написанный на динамических языках программирования, был разработан новый подход, который называется JIT-компиляцией (Just-In-Time-компиляция – компиляция «на лету»). Этот подход сочетает в себе лучшие качества интерпретирования и компиляции.
V8 можнет использовать интерпретирование в качестве основного метода и находить функции, которые используются чаще, чем остальные, и компилировать их, используя информацию о типах из предыдущих запусков программы.
Однако существует вероятность того, что тип изменится. Вместе с тем, нам нужно деоптимизировать скомпилированный код и повторно запустить интерпретирование (после этого, когда мы получим обратную связь нового типа, мы можем снова скомпилировать функцию).
Давайте изучим каждую составляющую JIT-компиляции подробнее.
Интерпретатор
V8 использует интерпретатор, который называется Ignition. Прежде всего он берет дерево абстрактного синтаксического анализа и генерирует байт-код.
У команд байт-кода также есть метаданные, такие как позиции исходной строки для дальнейшей отладки. Как правило, команды байт-кода согласуются с абстракциями JS.
А теперь возьмем наш пример и сгенерируем байт-код для него вручную:
LdaSmi #1 // write 1 to accumulator {записывает 1 в аккумулятор}
Star r0 // read to r0 (bar) from accumulator {считывает (bar) в r0 из аккумулятора}
Ldar r0 // write from r0 (bar) to accumulator {записывает (bar) из r0 в аккумулятор}
Return // returns accumulator (возвращает аккумулятор)
В Ignition есть нечто, что называется аккумулятором – место, где вы можете хранить или откуда вы можете считывать значения.
Аккумулятор позволяет избежать ситуаций, когда необходимо добавлять и вытаскивать вершину стека. Он также является неявно определенным аргументом для многих байт-кодов и, как правило, хранит результат операции. Return неявно возвращает аккумулятор.
Весь доступный байт-код вы можете извлечь из соответствующего исходного кода.
Выполнение
После того, как будет сгенерирован байт-код, Ignition будет интерпретировать команды с помощью таблицы обработчиков с доступом по ключу в виде байт-кода. Для каждого байт-кода Ignition может найти соответствующие функции-обработчики и выполнить их с предлагаемыми аргументами.
Как уже упоминалось ранее, этап выполнения также предоставляет обратную связь типа кода. Давайте разберемся, как это все получается и как этим управлять.
Для начала, обсудим, как объекты JavaScript могу быть представлены в памяти. При самом простом подходе мы можем создать словарь для каждого объекта и связать его с памятью.
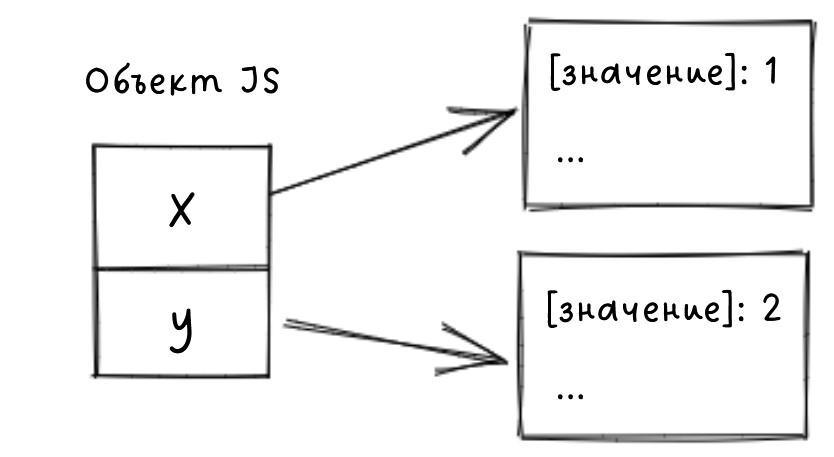
Первый подход к хранению объектов
Однако, как правило, есть много объектов с одинаковой структурой, поэтому хранить большое количество одинаковых словарей будет неэффективно.
Для того, чтобы избежать таких ситуаций, V8 отделяет структуру объекта от самих значений с помощью форм объектов (Map) и вектора значений в памяти.
Например, мы создаем объектный литерал:
let c = { x: 3 }
let d = { x: 5 }
c.y = 4
В первой строке он создаст форму Map[c], которая имеет свойство x со смещением 0.
Во второй строке V8 будет повторно использовать ту же форму для новой переменной.
После третьей строки он создаст новую форму Map[c1], у которой будет свойство y со смещением 1, а также ссылку на предыдущую форму Map[c].
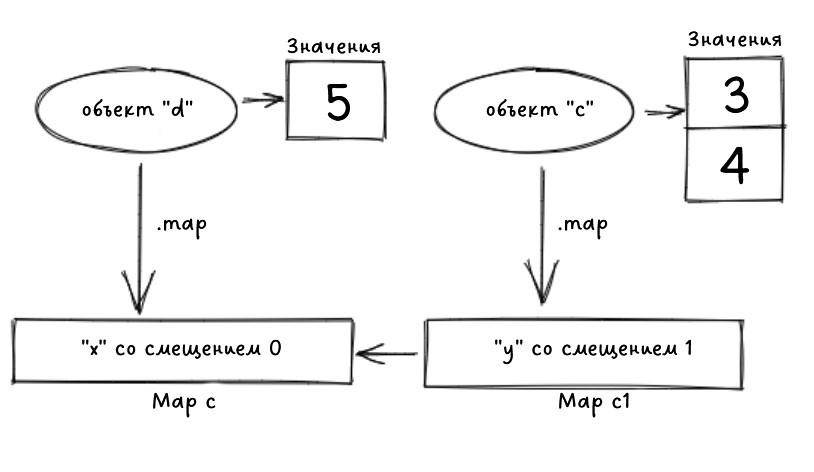
Пример форм объектов
В приведенном выше примере каждый объект может иметь ссылку на форму объекта, где для каждого свойства V8 может найти смещение для значения, хранящегося в памяти.
Формы объектов – это, по сути, связные списки. То есть, если вы напишите c.x, то V8 перейдет в начало списка, найдет там y, перейдет к связанной форме и, наконец, получит x и считает из него смещение. После чего он перейдет к вектору памяти и вернет из него первый элемент.
Как вы уже могли понять, в большом веб-приложении будет огромное количество таких связных форм. И при этом на выполнение поиска по связному списку затрачивается линейное время, что делает поиск свойств достаточно затратной операцией.
Для того, чтобы решить данную проблему в V8, вы можете использовать встроенный кэш (IC – Inline Cache). В нем сохраняется информация о том, где можно найти свойства объектов. Таким образом, количество поисков сокращается.
Вы можете представить, что это некое прослушивающее устройство в вашем коде: он отслеживает все события CALL, STORE и LOAD внутри функции и записывает все проходящие через нее формы.
Структура данных, которая используется для хранения IC, называется вектором обратной связи. Это просто массив, в котором хранятся все IC функции.
function load(a) {
return a.key;
}
Для функции выше вектор обратной связи будет выглядеть следующим образом:
[{ slot: 0, icType: LOAD, value: UNINIT }]
Это простая функция, у которой есть только один IC, который имеет тип LOAD и значение UNINIT. Это значит, что он не был инициализирован, и мы не знаем, что будет происходить дальше.
Давайте вызовем эту функцию, передав ей другие аргументы, и посмотрим, как изменится встроенный кэш.
let first = { key: 'first' } // shape A {форма А}
let fast = { key: 'fast' } // the same shape A {та же форма А}
let slow = { foo: 'slow' } // new shape B {новая форма В}
load(first)
load(fast)
load(slow)
После первого вызова функции load наш встроенный кэш получит обновленное значение:
[{ slot: 0, icType: LOAD, value: MONO(A) }]
Теперь это значение стало мономорфным, а это значит, то кэш разрешается только в форму А.
После второго вызова V8 проверит значение IC и увидит, что оно мономорфно и имеет ту же форму, что и переменная fast. В связи с чем, он тут же вернет смещение и разрешит его.
При третьем вызове форма будет отличаться от сохраненной. Поэтому V8 вручную разрешит его и обновит значение до «полиморфный» с помощью массива из двух возможных форм.
[{ slot: 0, icType: LOAD, value: POLY[A,B] }]
Теперь при каждом вызове этой функции V8 должен проверять не одну форму, а перебрать несколько вариантов.
Для того, чтобы ускорить ваш код, вы можете инициализировать объекты одинаковыми типами и не слишком усердствовать, меняя их структуру.
Примечание: возьмите это на заметку, но если это может привести к дублированию кода или если ваш код станет менее выразительным, то не делайте этого.
Встроенные кэши также отслеживают то, как часто они вызываются, чтобы понять, хорошо ли Turbofan справляется с оптимизацией компилятора.
Компилятор
Ignition помогает только до определенного времени. Если функция становится достаточно медленной, то она оптимизируется в компиляторе Turbofan.
Turbofan берет байт-код из Ignition и обратную связь типа (вектор обратной связи) функции, применяет набор преобразований на его основе и выдает машинный код.
И как мы уже видели до этого, обратная связь типа не всегда гарантирует, что функция останется неизменной.
Например, код, который был оптимизирован с помощью Turbofan, основан на том предположении, что некоторая операция сложения всегда прибавляет целые числа.
Но что будет, если функция получит строку? Этот процесс называется деоптимизацией. Мы отбрасываем оптимизированный код, возвращаемся к интерпретируемому, возобновляем выполнение и обновляем обратную связь типа.
Подведем итог
В этой статье мы рассмотрели реализацию движка JS и четкие этапы выполнения кода на JavaScript.
Подведем итог и взглянем на процесс компиляции, так сказать, сверху.
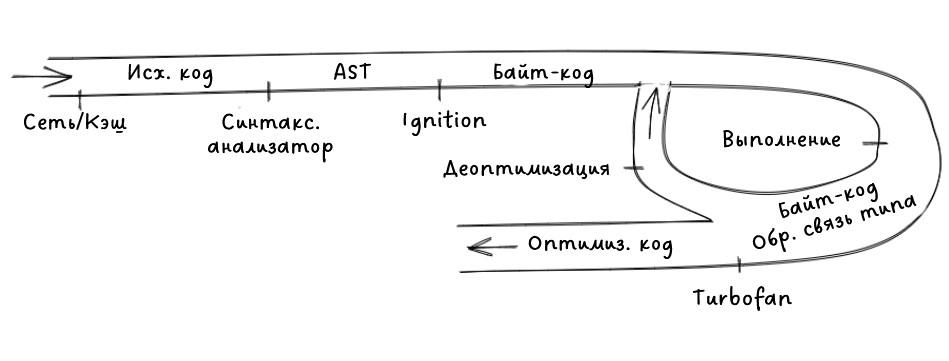
Общая схема V8
Рассмотрим процесс шаг за шагом:
- Все начинается с того, что мы получаем код JavaScript из сети.
- V8 анализирует код с точки зрения синтаксиса и превращает его в дерево абстрактного синтаксического анализа (AST).
- Беря за основу это дерево AST, интерпретатор Ignition может приступить к своей работе и начать формировать байт-код.
- На этом этапе движок запускает код и собирает обратную связь типов.
- Чтобы ускорить работу, байт-код можно отправить оптимизирующему компилятору вместе с данными обратной связи. Оптимизирующий компилятор создает на его основе некие предположения, после чего выдает высокооптимизированный машинный код.
- Если в какой-то момент оказывается, что одно из предположений неверно, то оптимизирующий компилятор деоптимизирует код и возвращается к интерпретатору.
